Publications tagged "Imitation learning"
Conferences
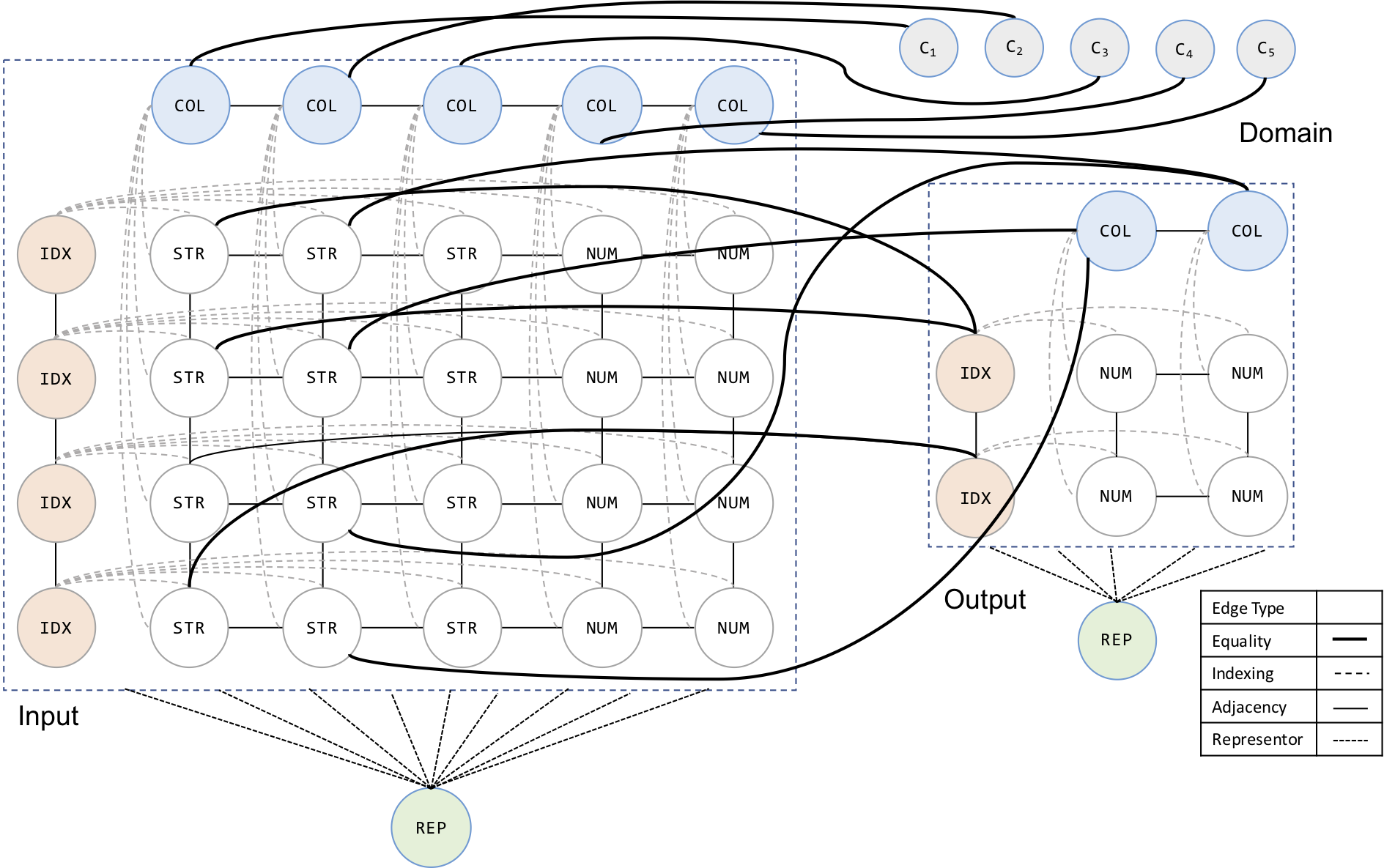
AutoPandas: Neural-Backed Generators for Program Synthesis
Rohan Bavishi, Caroline Lemieux, Roy Fox, Koushik Sen, and Ion Stoica
10th ACM SIGPLAN Conference on Systems, Programming, Languages, and Applications: Software for Humanity (SPLASH OOPSLA), 2019
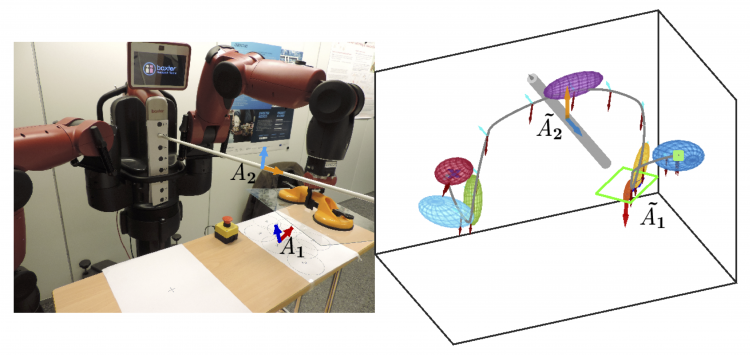
Multi-Task Hierarchical Imitation Learning for Home Automation
Roy Fox*, Ron Berenstein*, Ion Stoica, and Ken Goldberg
15th IEEE Conference on Automation Science and Engineering (CASE), 2019
Generalizing Robot Imitation Learning with Invariant Hidden Semi-Markov Models
Ajay Kumar Tanwani, Jonathan Lee, Brijen Thananjeyan, Michael Laskey, Sanjay Krishnan, Roy Fox, Ken Goldberg, and Sylvain Calinon
13th International Workshop on the Algorithmic Foundations of Robotics (WAFR), 2018
Constraint Estimation and Derivative-Free Recovery for Robot Learning from Demonstrations
Jonathan Lee, Michael Laskey, Roy Fox, and Ken Goldberg
14th IEEE Conference on Automation Science and Engineering (CASE), 2018
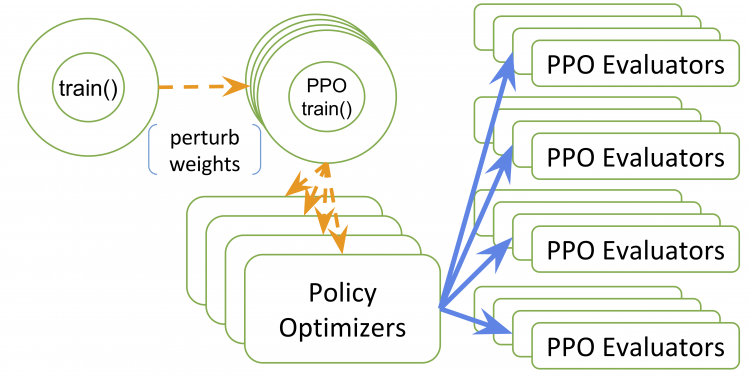
RLlib: Abstractions for Distributed Reinforcement Learning
Eric Liang*, Richard Liaw*, Robert Nishihara, Philipp Moritz, Roy Fox, Ken Goldberg, Joseph Gonzalez, Michael Jordan, and Ion Stoica
35th International Conference on Machine Learning (ICML), 2018
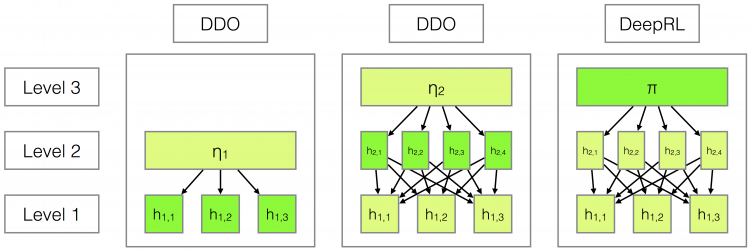
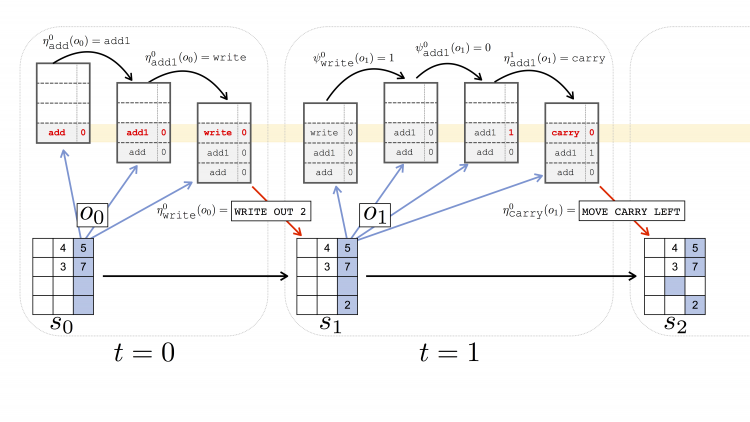
Parametrized Hierarchical Procedures for Neural Programming
Roy Fox, Richard Shin, Sanjay Krishnan, Ken Goldberg, Dawn Song, and Ion Stoica
6th International Conference on Learning Representations (ICLR), 2018
DDCO: Discovery of Deep Continuous Options for Robot Learning from Demonstrations
Sanjay Krishnan*, Roy Fox*, Ion Stoica, and Ken Goldberg
1st Conference on Robot Learning (CoRL), 2017
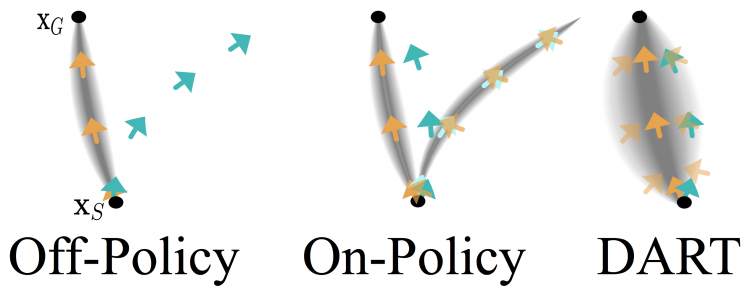
DART: Noise Injection for Robust Imitation Learning
Michael Laskey, Jonathan Lee, Roy Fox, Anca Dragan, and Ken Goldberg
1st Conference on Robot Learning (CoRL), 2017
An Algorithm and User Study for Teaching Bilateral Manipulation via Iterated Best Response Demonstrations
Carolyn Chen, Sanjay Krishnan, Michael Laskey, Roy Fox, and Ken Goldberg
13th IEEE Conference on Automation Science and Engineering (CASE), 2017
Statistical Data Cleaning for Deep Learning of Automation Tasks from Demonstrations
Caleb Chuck, Michael Laskey, Sanjay Krishnan, Ruta Joshi, Roy Fox, and Ken Goldberg
13th IEEE Conference on Automation Science and Engineering (CASE), 2017
Workshops
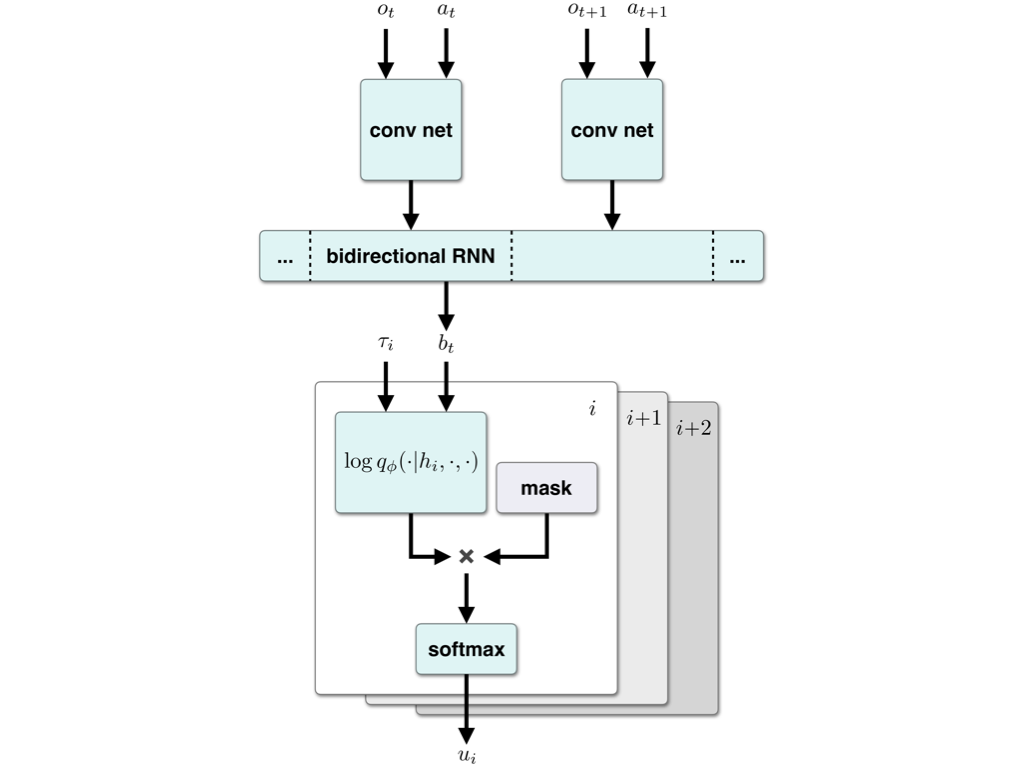
Hierarchical Imitation Learning via Variational Inference of Control Programs
Roy Fox, Richard Shin, William Paul, Yitian Zou, Dawn Song, Ken Goldberg, Pieter Abbeel, and Ion Stoica
Infer to Control: Probabilistic Reinforcement Learning and Structured Control workshop (Infer2Control @ NeurIPS), 2018
Neural Inference of API Functions from Input–Output Examples
Rohan Bavishi, Caroline Lemieux, Neel Kant, Roy Fox, Koushik Sen, and Ion Stoica
Machine Learning for Systems workshop (ML for Sys @ NeurIPS), 2018
Imitation Learning of Hierarchical Programs via Variational Inference
Roy Fox*, Richard Shin*, Pieter Abbeel, Ken Goldberg, Dawn Song, and Ion Stoica
Neural Abstract Machines & Program Induction workshop (NAMPI @ ICML), 2018
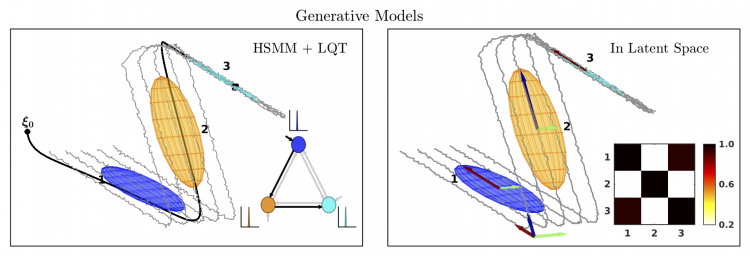
Robot Learning with Invariant Hidden Semi-Markov Models
Ajay Kumar Tanwani, Jonathon Lee, Michael Laskey, Sanjay Krishnan, Roy Fox, and Ken Goldberg
Perspectives on Robot Learning: Imitation and Causality workshop (Causal Imit. @ RSS), 2018
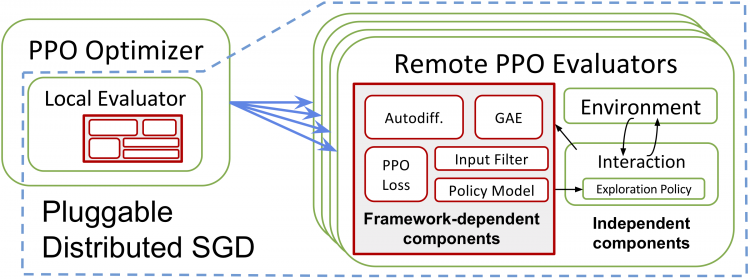
Ray RLlib: A Composable and Scalable Reinforcement Learning Library
Eric Liang*, Richard Liaw*, Robert Nishihara, Philipp Moritz, Roy Fox, Joseph Gonzalez, Ken Goldberg, and Ion Stoica
Deep Reinforcement Learning symposium (DeepRL @ NeurIPS), 2017
Preprints
Hierarchical Variational Imitation Learning of Control Programs
Roy Fox, Richard Shin, William Paul, Yitian Zou, Dawn Song, Ken Goldberg, Pieter Abbeel, and Ion Stoica
arXiv:1912.12612, 2019