Publications tagged "Reinforcement learning"
Conferences
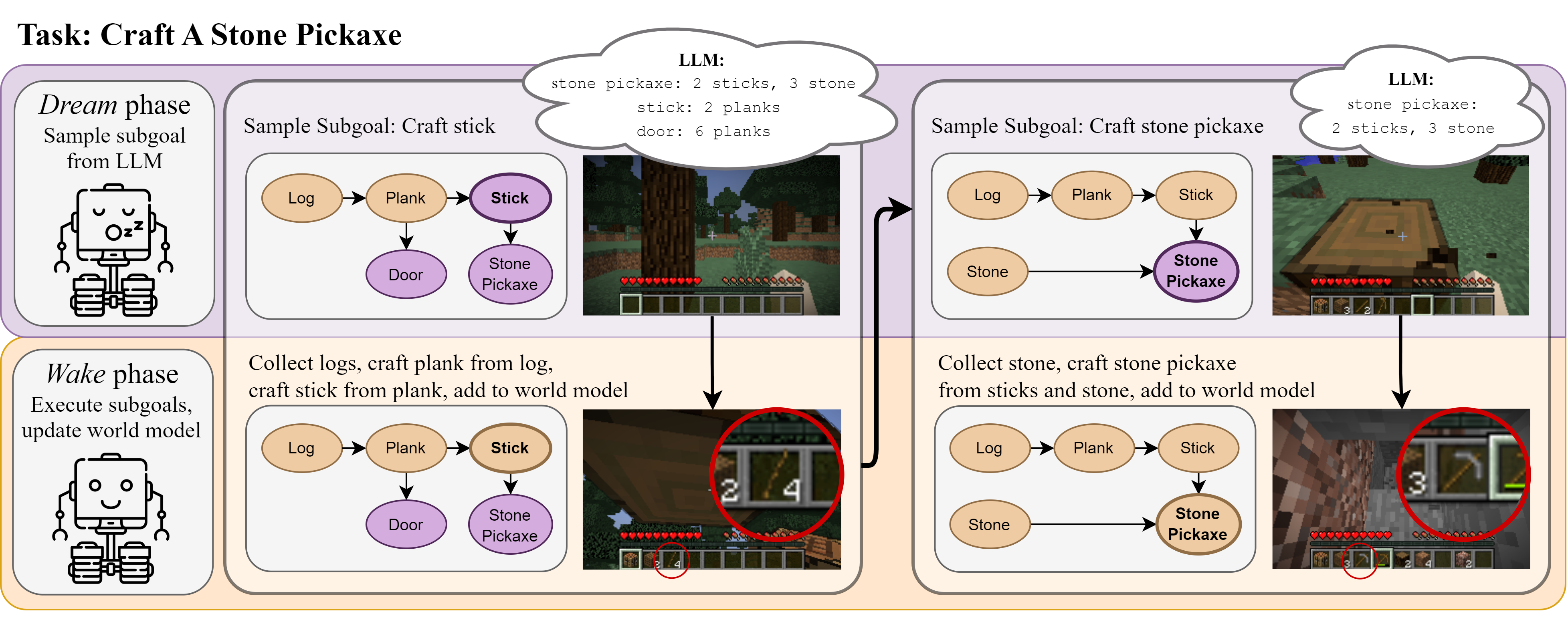
Do Embodied Agents Dream of Pixelated Sheep?: Embodied Decision Making using Language Guided World Modelling
Kolby Nottingham, Prithviraj Ammanabrolu, Alane Suhr, Yejin Choi, Hannaneh Hajishirzi, Sameer Singh, and Roy Fox
40th International Conference on Machine Learning (ICML), 2023
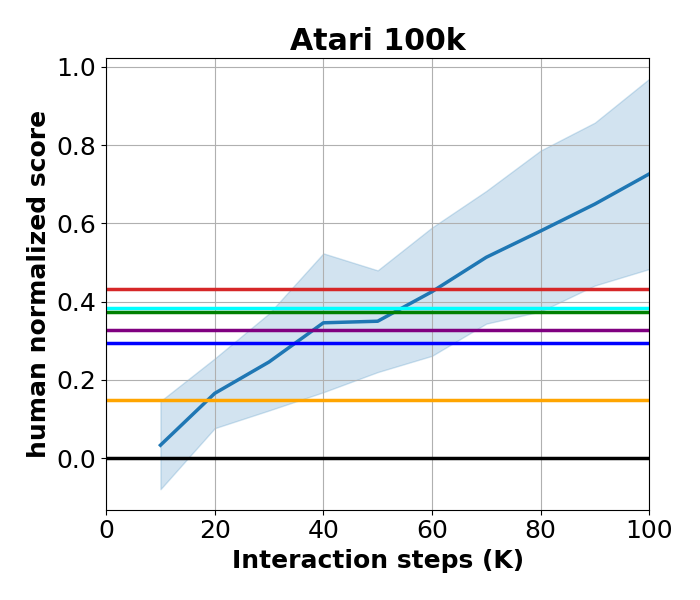
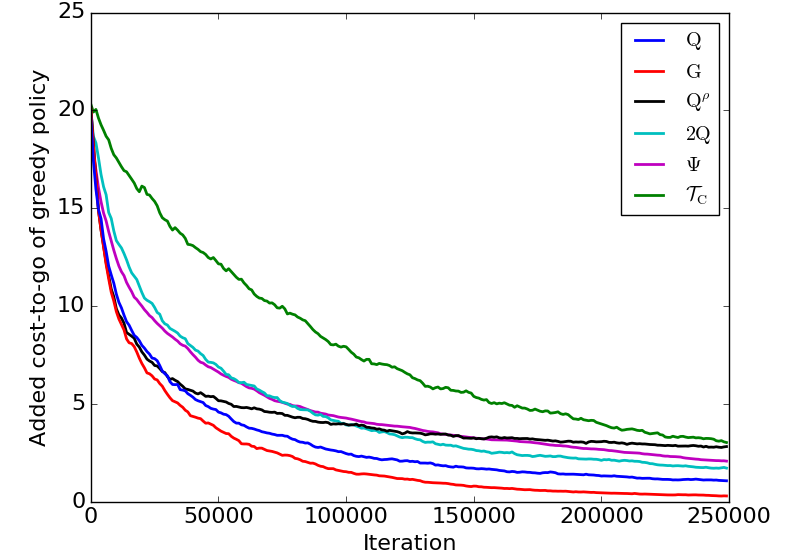
Reducing Variance in Temporal-Difference Value Estimation via Ensemble of Deep Networks
Litian Liang, Yaosheng Xu, Stephen McAleer, Dailin Hu, Alexander Ihler, Pieter Abbeel, and Roy Fox
39th International Conference on Machine Learning (ICML), 2022
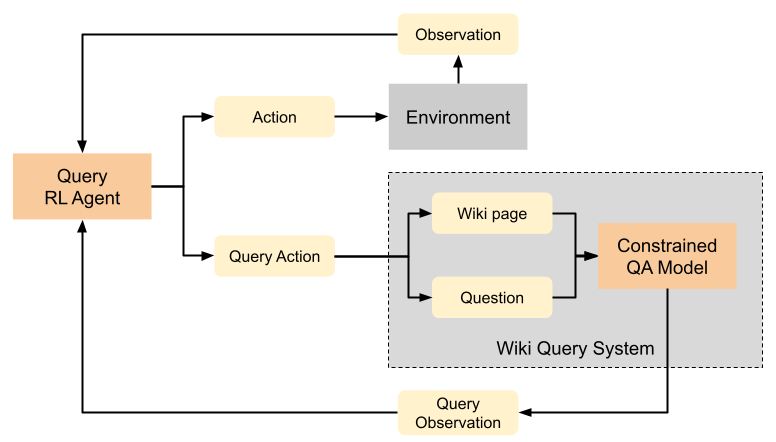
Learning to Query Internet Text for Informing Reinforcement Learning Agents
Kolby Nottingham, Alekhya Pyla, Sameer Singh, and Roy Fox
Reinforcement Learning and Decision Making (RLDM), 2022
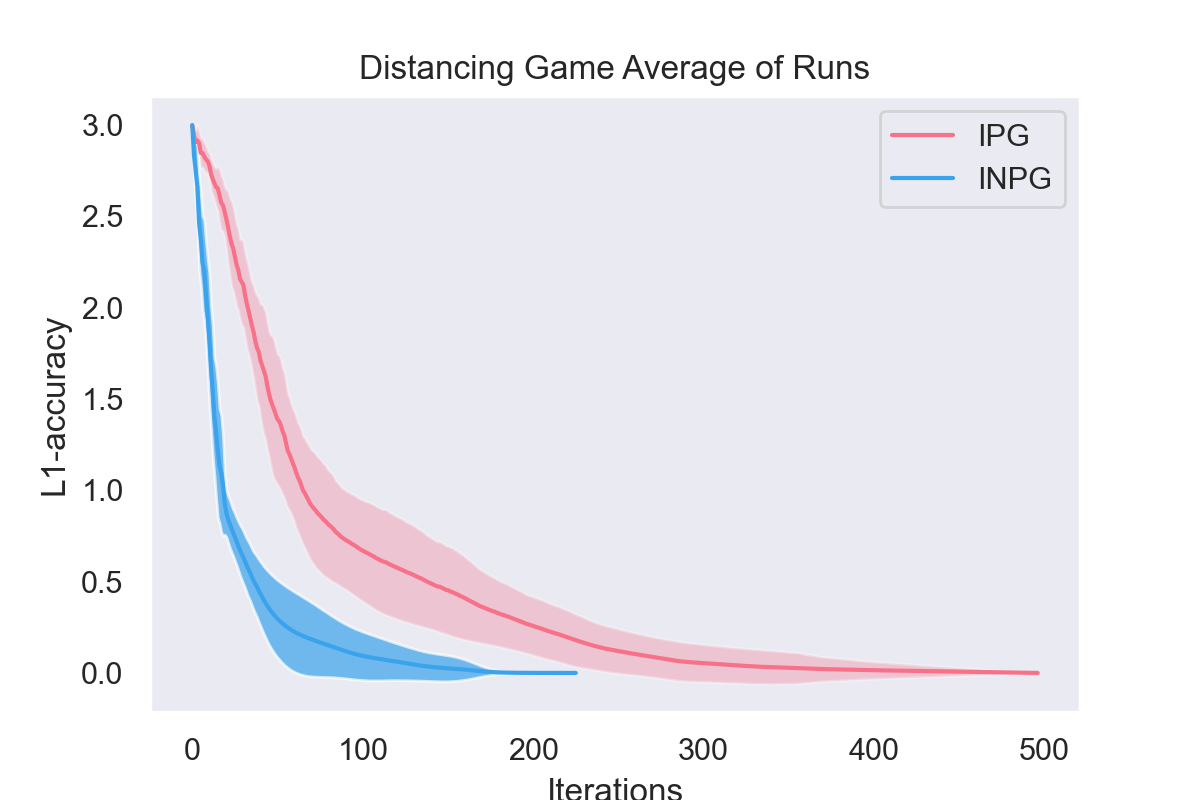
Independent Natural Policy Gradient Always Converges in Markov Potential Games
Roy Fox, Stephen McAleer, William Overman, and Ioannis Panageas
25th International Conference on Artificial Intelligence and Statistics (AISTATS), 2022
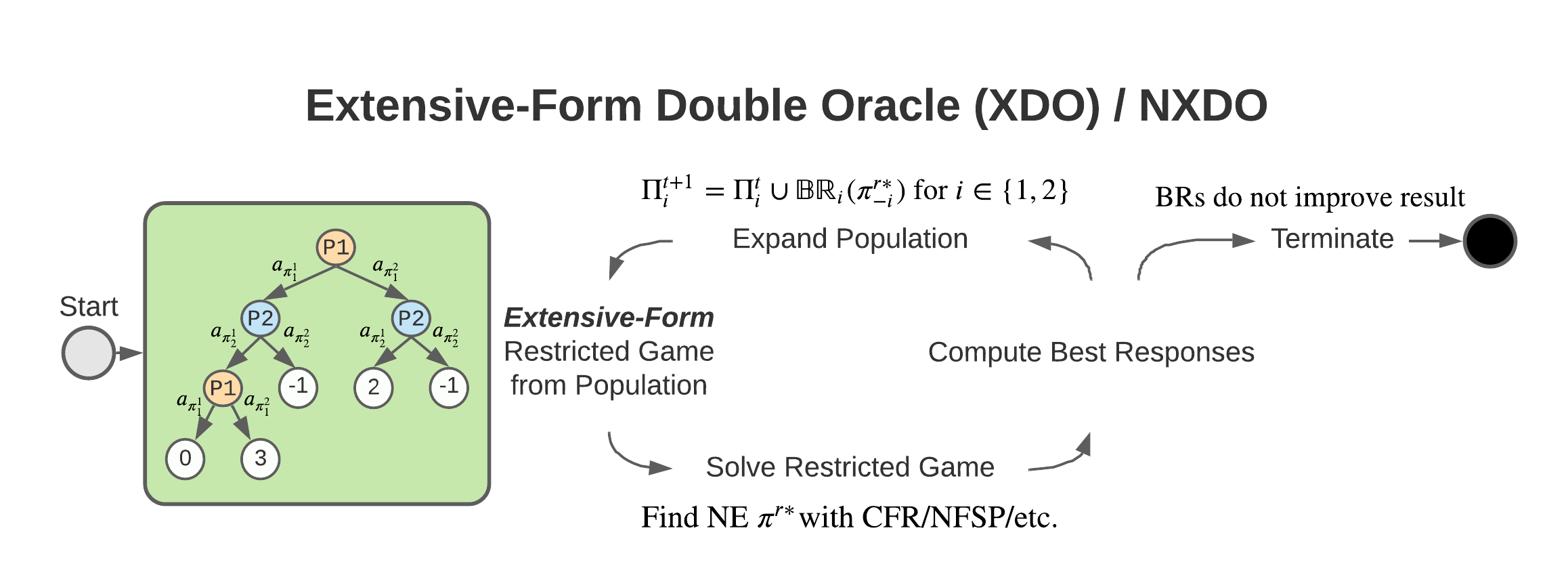
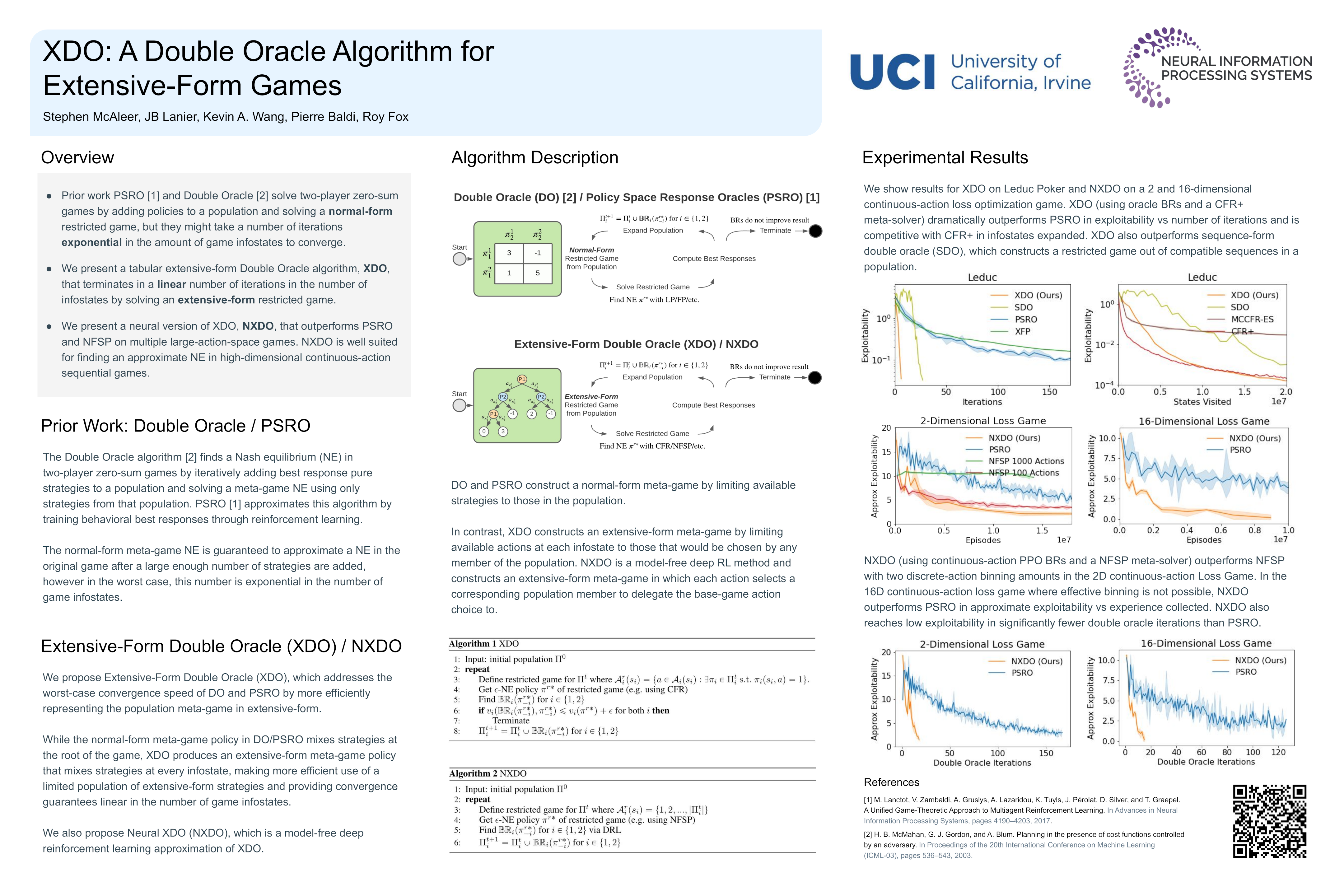
XDO: A Double Oracle Algorithm for Extensive-Form Games
Stephen McAleer, JB Lanier, Kevin Wang, Pierre Baldi, and Roy Fox
35th Conference on Neural Information Processing Systems (NeurIPS), 2021
Pipeline PSRO: A Scalable Approach for Finding Approximate Nash Equilibria in Large Games
Stephen McAleer*, JB Lanier*, Roy Fox, and Pierre Baldi
34th Conference on Neural Information Processing Systems (NeurIPS), 2020
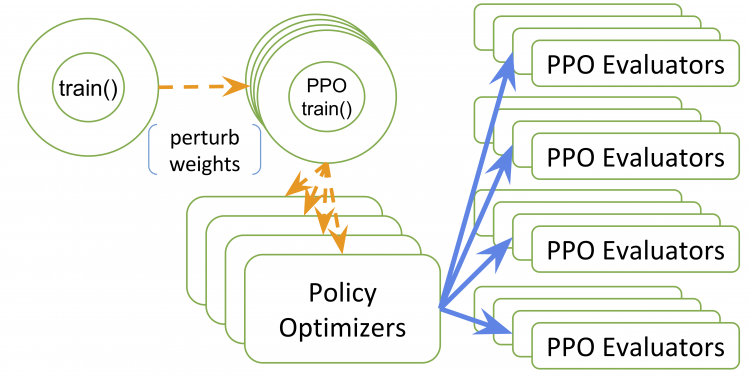
RLlib: Abstractions for Distributed Reinforcement Learning
Eric Liang*, Richard Liaw*, Robert Nishihara, Philipp Moritz, Roy Fox, Ken Goldberg, Joseph Gonzalez, Michael Jordan, and Ion Stoica
35th International Conference on Machine Learning (ICML), 2018
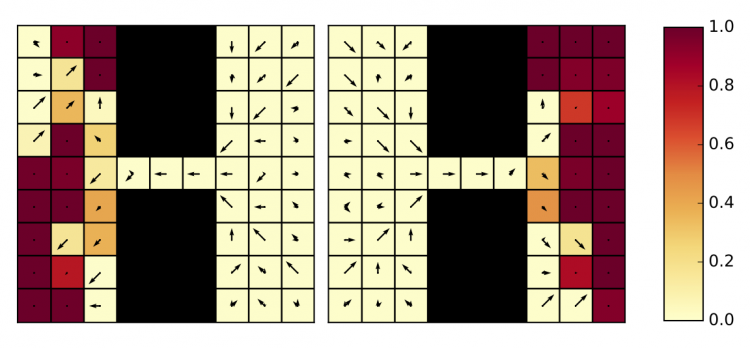
Principled Option Learning in Markov Decision Processes
Roy Fox*, Michal Moshkovitz*, and Naftali Tishby
13th European Workshop on Reinforcement Learning (EWRL), 2016
Taming the Noise in Reinforcement Learning via Soft Updates
Roy Fox*, Ari Pakman*, and Naftali Tishby
32nd Conference on Uncertainty in Artificial Intelligence (UAI), 2016
Workshops
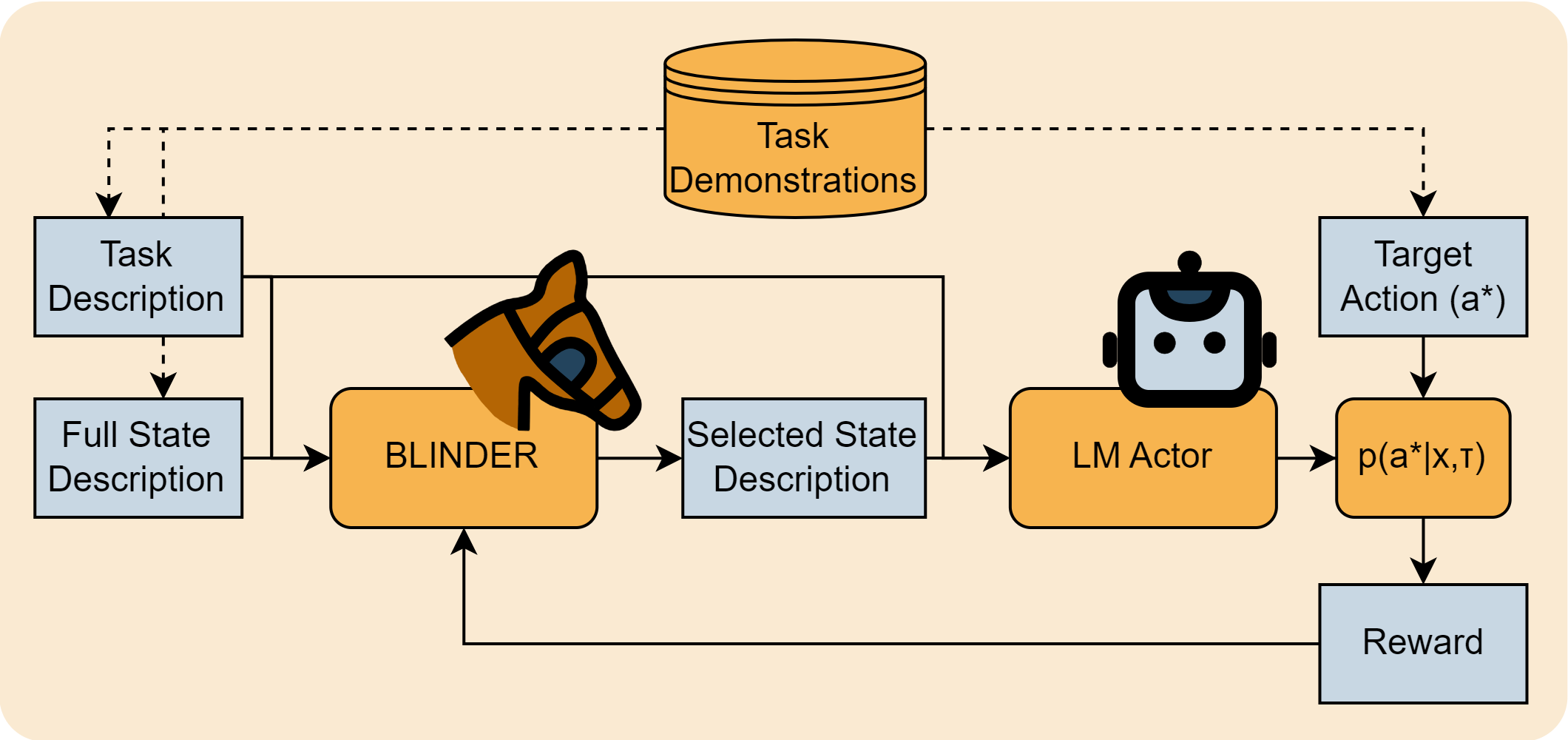
Selective Perception: Learning Concise State Descriptions for Language Model Actors
Kolby Nottingham, Yasaman Razeghi, Kyungmin Kim, JB Lanier, Pierre Baldi, Roy Fox, and Sameer Singh
Foundation Models for Decision Making workshop (FMDM @ NeurIPS), 2023
Do Embodied Agents Dream of Pixelated Sheep?: Embodied Decision Making using Language Guided World Modelling
Kolby Nottingham, Prithviraj Ammanabrolu, Alane Suhr, Yejin Choi, Hannaneh Hajishirzi, Sameer Singh, and Roy Fox
Reincarnating Reinforcement Learning workshop (RRL @ ICLR), 2023
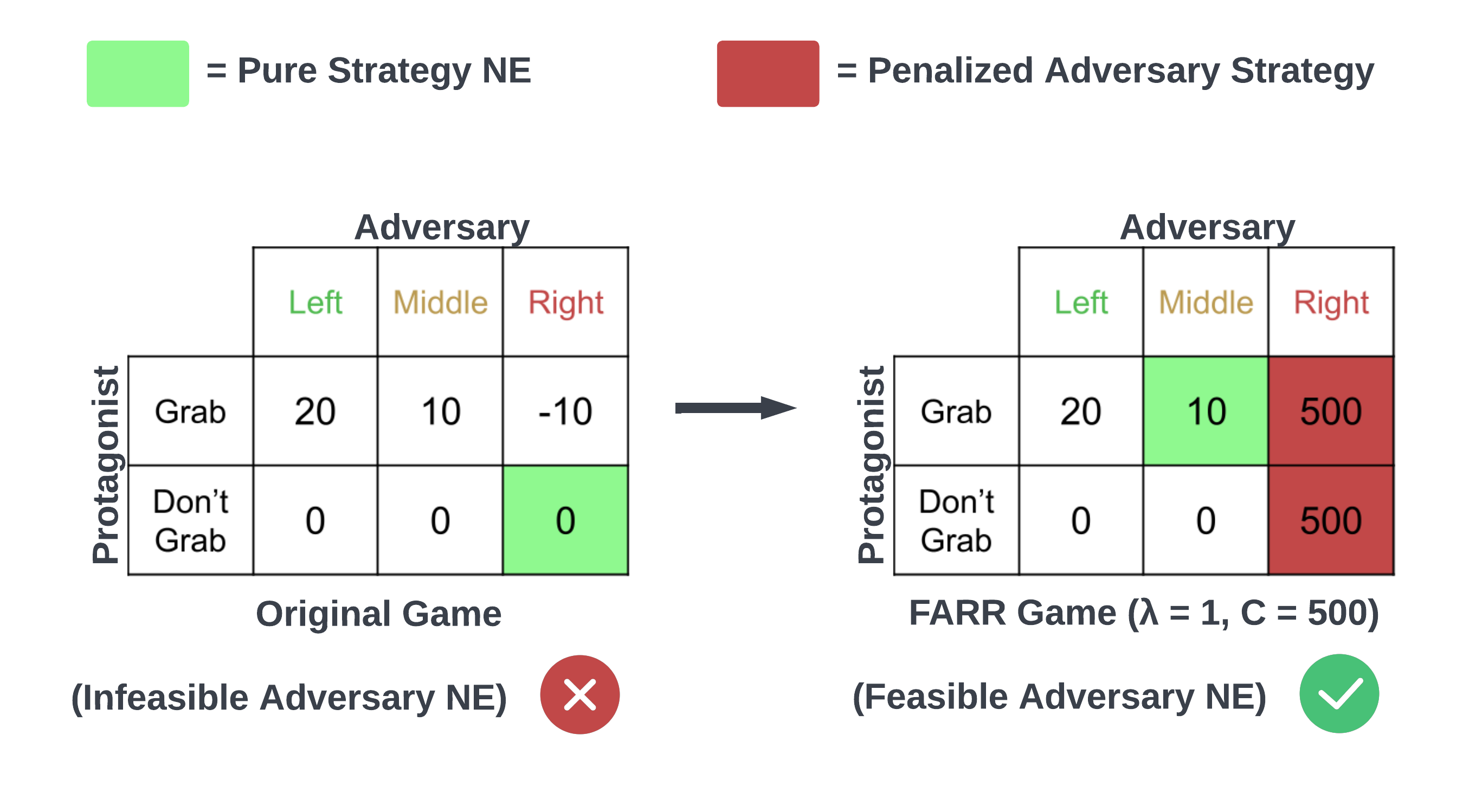
Feasible Adversarial Robust Reinforcement Learning for Underspecified Environments
JB Lanier, Stephen McAleer, Pierre Baldi, and Roy Fox
Deep Reinforcement Learning workshop (DRL @ NeurIPS), 2022
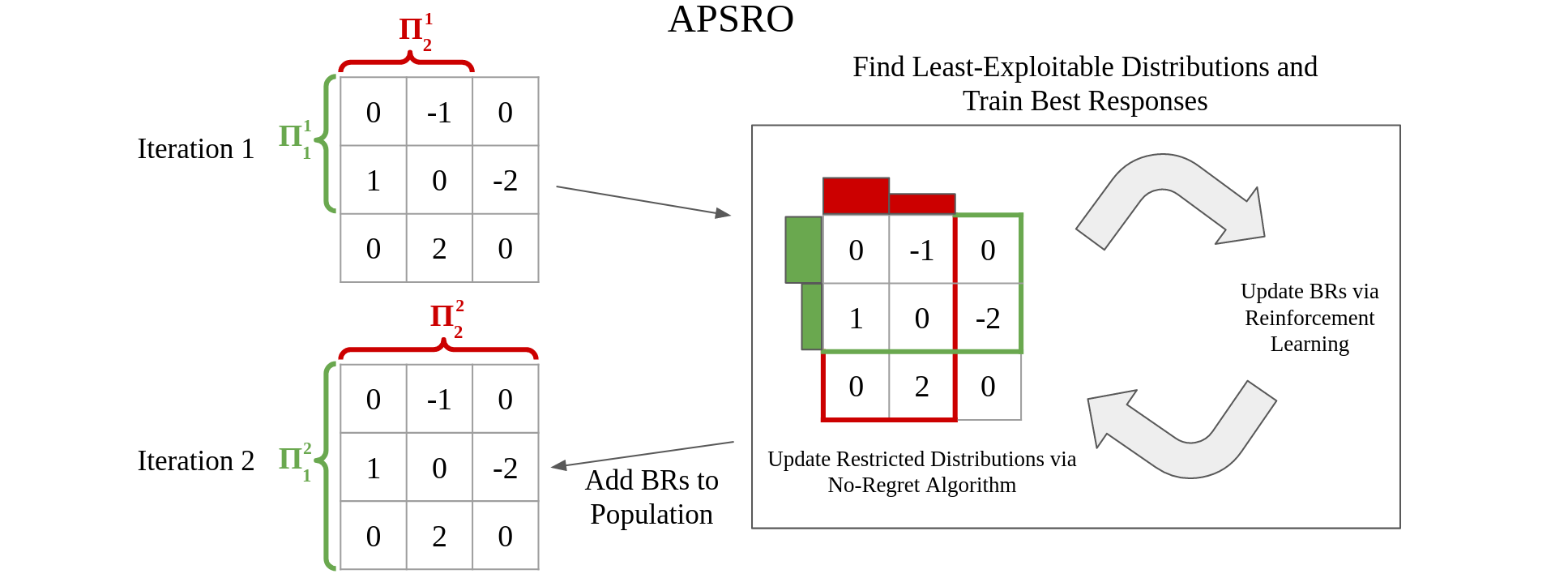
Anytime PSRO for Two-Player Zero-Sum Games
Stephen McAleer, Kevin Wang, JB Lanier, Marc Lanctot, Pierre Baldi, Tuomas Sandholm, and Roy Fox
Reinforcement Learning in Games workshop (RLG @ AAAI), 2022
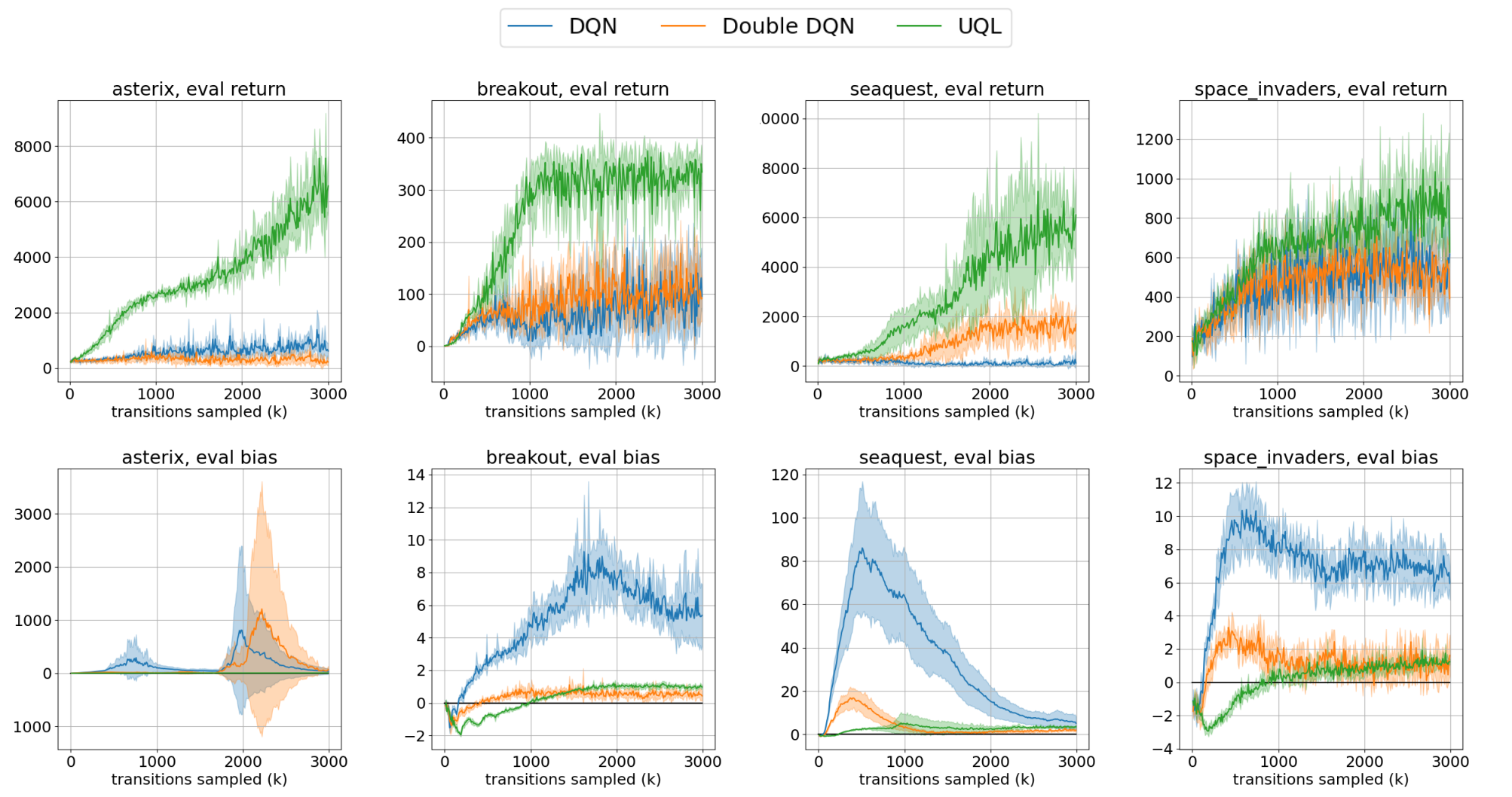
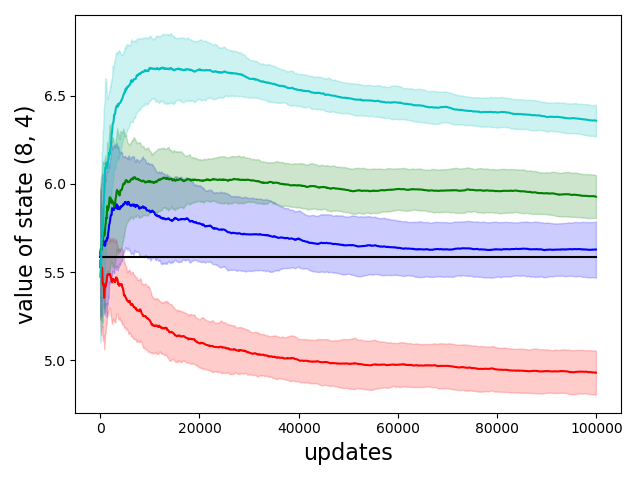
Temporal-Difference Value Estimation via Uncertainty-Guided Soft Updates
Litian Liang, Yaosheng Xu, Stephen McAleer, Dailin Hu, Alexander Ihler, Pieter Abbeel, and Roy Fox
Deep Reinforcement Learning workshop (DRL @ NeurIPS), 2021
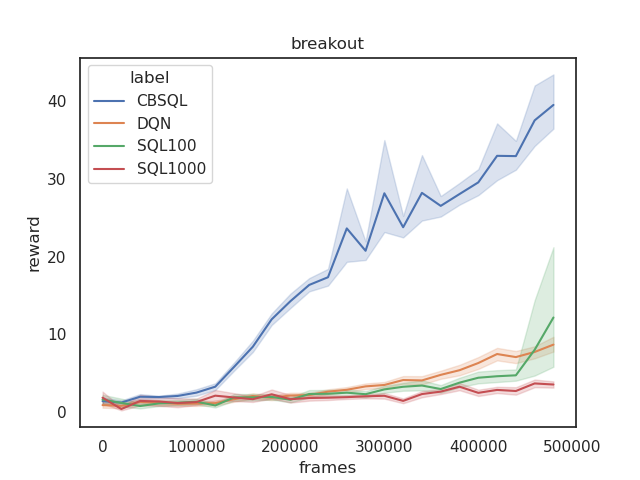
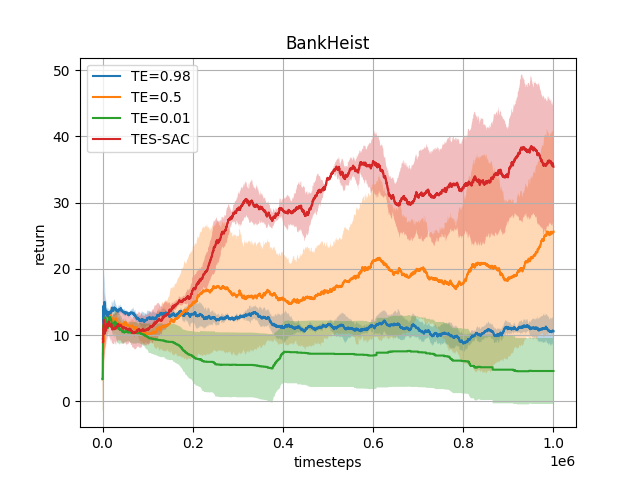
Target Entropy Annealing for Discrete Soft Actor–Critic
Yaosheng Xu, Dailin Hu, Litian Liang, Stephen McAleer, Pieter Abbeel, and Roy Fox
Deep Reinforcement Learning workshop (DRL @ NeurIPS), 2021
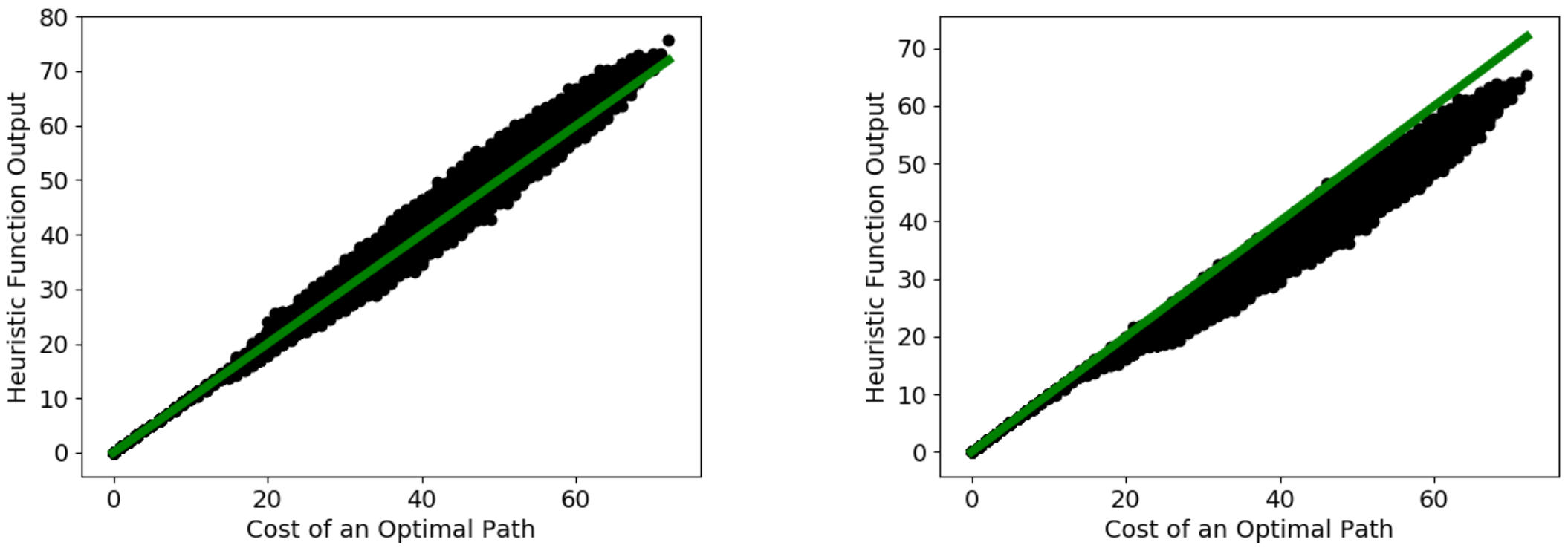
Obtaining Approximately Admissible Heuristic Functions through Deep Reinforcement Learning and A* Search
Forest Agostinelli, Stephen McAleer, Alexander Shmakov, Roy Fox, Marco Valtorta, Biplav Srivastava, and Pierre Baldi
Bridging the Gap between AI Planning and Reinforcement Learning workshop (PRL @ ICAPS), 2021
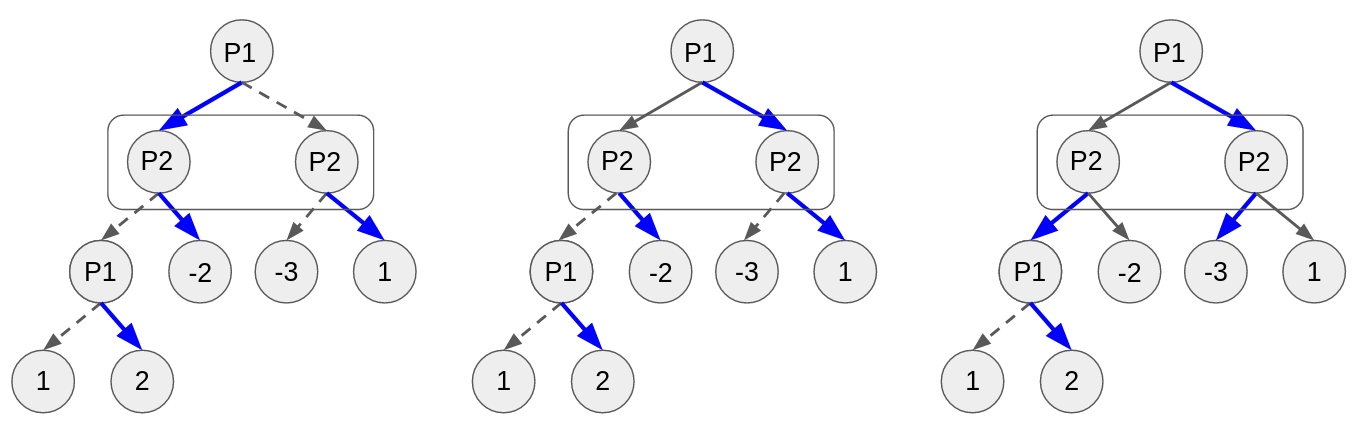
CFR-DO: A Double Oracle Algorithm for Extensive-Form Games
Stephen McAleer, JB Lanier, Pierre Baldi, and Roy Fox
Reinforcement Learning in Games workshop (RLG @ AAAI), 2021
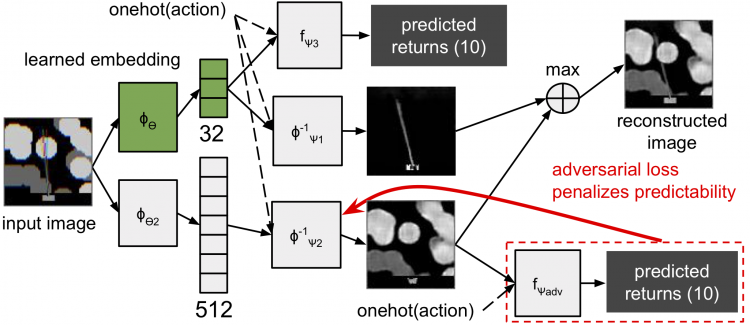
Task-Relevant Embeddings for Robust Perception in Reinforcement Learning
Eric Liang, Roy Fox, Joseph Gonzalez, and Ion Stoica
Prediction and Generative Modeling in Reinforcement Learning workshop (PGMRL @ ICML), 2018
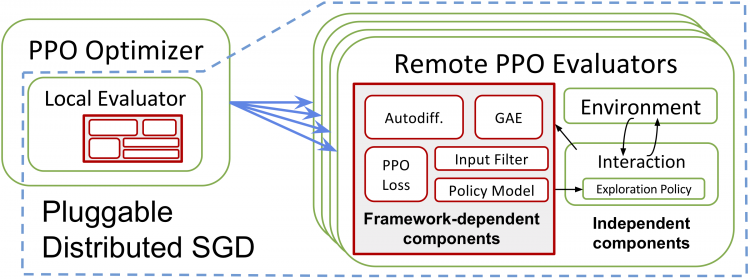
Ray RLlib: A Composable and Scalable Reinforcement Learning Library
Eric Liang*, Richard Liaw*, Robert Nishihara, Philipp Moritz, Roy Fox, Joseph Gonzalez, Ken Goldberg, and Ion Stoica
Deep Reinforcement Learning symposium (DeepRL @ NeurIPS), 2017
Theses
Preprints
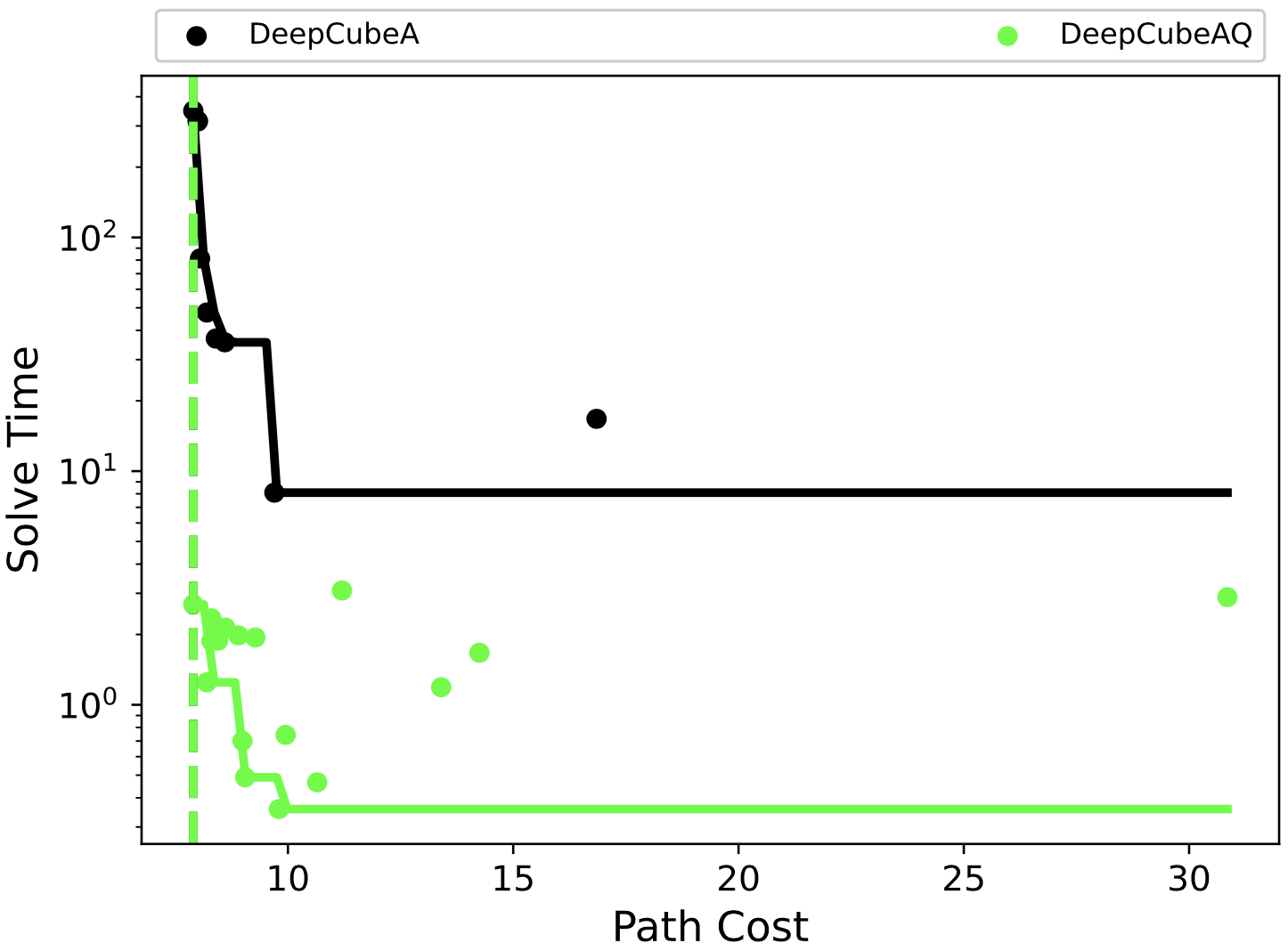
A* Search Without Expansions: Learning Heuristic Functions with Deep Q-Networks
Forest Agostinelli, Alexander Shmakov, Stephen McAleer, Roy Fox, and Pierre Baldi
arXiv:2102.04518, 2021
{kind=link}