Publications tagged "Robotics"
Conferences
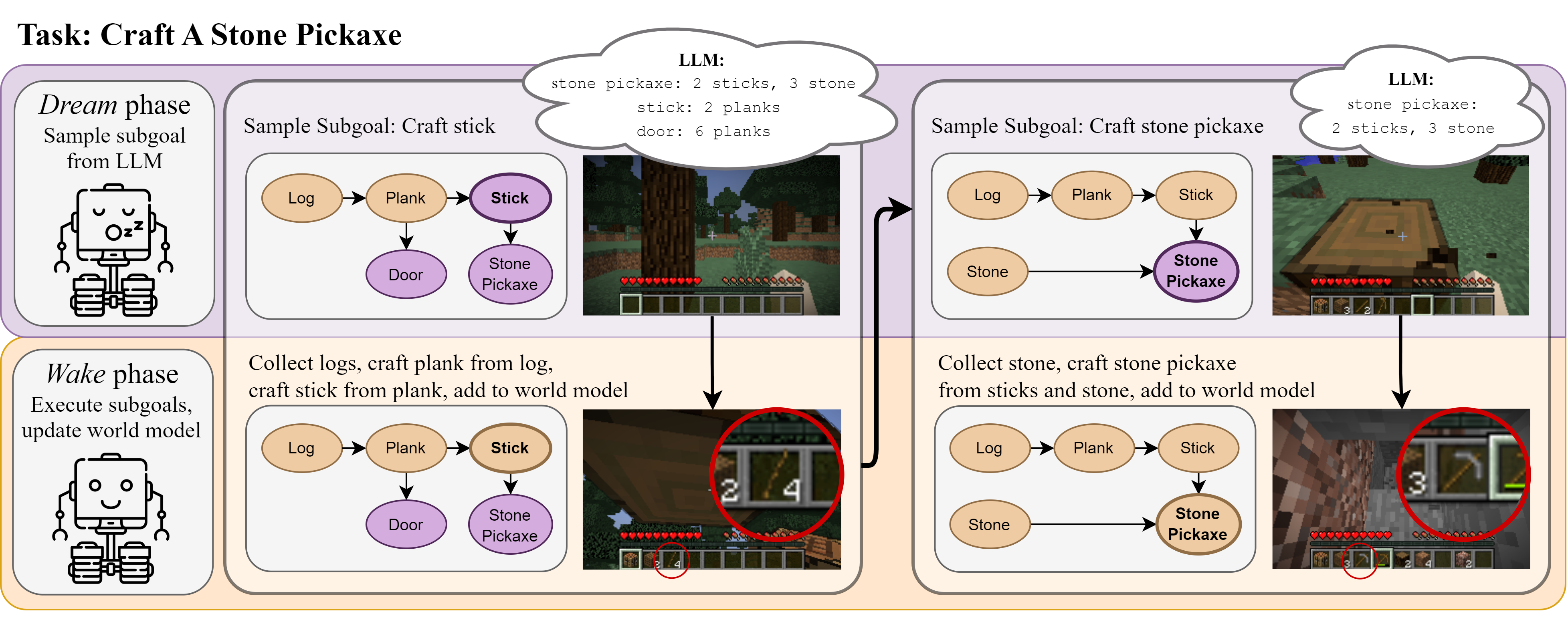
Do Embodied Agents Dream of Pixelated Sheep?: Embodied Decision Making using Language Guided World Modelling
Kolby Nottingham, Prithviraj Ammanabrolu, Alane Suhr, Yejin Choi, Hannaneh Hajishirzi, Sameer Singh, and Roy Fox
40th International Conference on Machine Learning (ICML), 2023
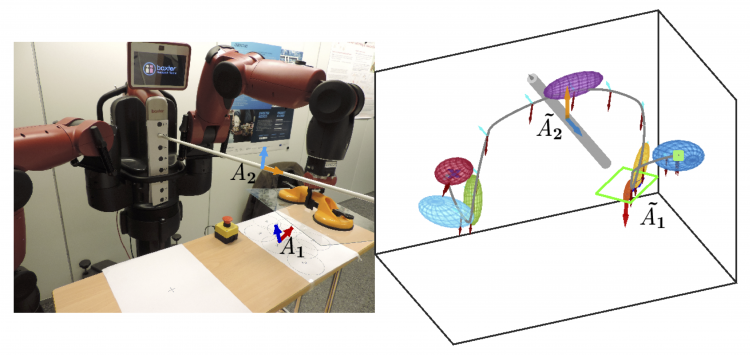
Multi-Task Hierarchical Imitation Learning for Home Automation
Roy Fox*, Ron Berenstein*, Ion Stoica, and Ken Goldberg
15th IEEE Conference on Automation Science and Engineering (CASE), 2019
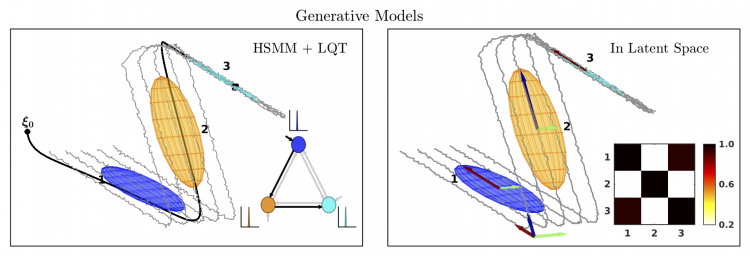
Generalizing Robot Imitation Learning with Invariant Hidden Semi-Markov Models
Ajay Kumar Tanwani, Jonathan Lee, Brijen Thananjeyan, Michael Laskey, Sanjay Krishnan, Roy Fox, Ken Goldberg, and Sylvain Calinon
13th International Workshop on the Algorithmic Foundations of Robotics (WAFR), 2018
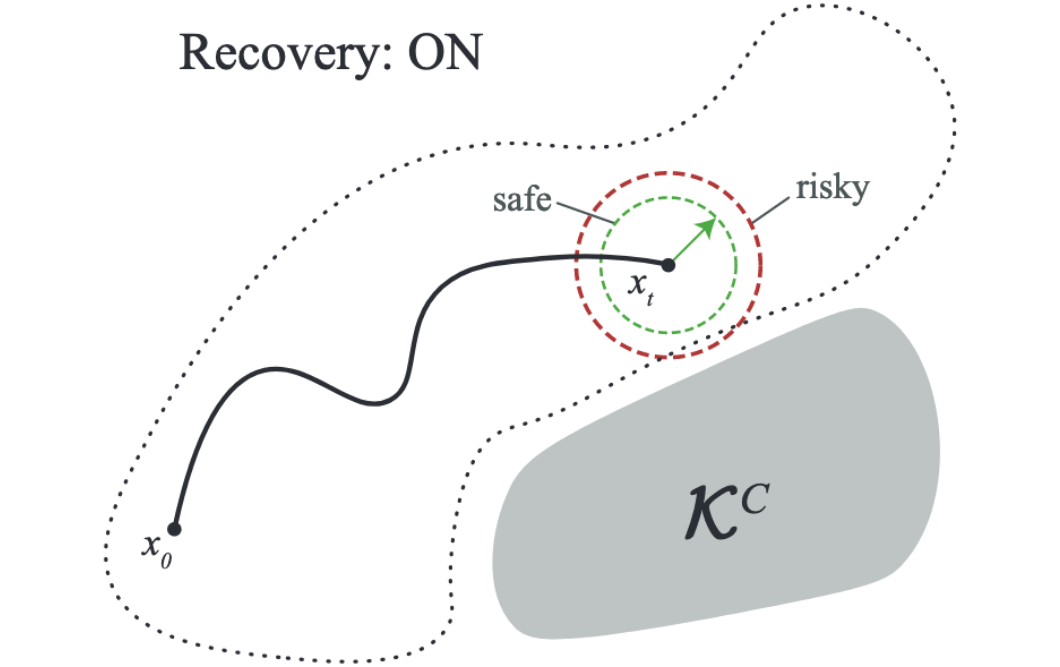
Constraint Estimation and Derivative-Free Recovery for Robot Learning from Demonstrations
Jonathan Lee, Michael Laskey, Roy Fox, and Ken Goldberg
14th IEEE Conference on Automation Science and Engineering (CASE), 2018
Fast and Reliable Autonomous Surgical Debridement with Cable-Driven Robots Using a Two-Phase Calibration Procedure
Daniel Seita, Sanjay Krishnan, Roy Fox, Stephen McKinley, John Canny, and Ken Goldberg
35th IEEE International Conference on Robotics and Automation (ICRA), 2018
Robustly Adjusting Indoor Drip Irrigation Emitters with the Toyota HSR Robot
Ron Berenstein, Roy Fox, Stephen McKinley, Stefano Carpin, and Ken Goldberg
35th IEEE International Conference on Robotics and Automation (ICRA), 2018
DDCO: Discovery of Deep Continuous Options for Robot Learning from Demonstrations
Sanjay Krishnan*, Roy Fox*, Ion Stoica, and Ken Goldberg
1st Conference on Robot Learning (CoRL), 2017
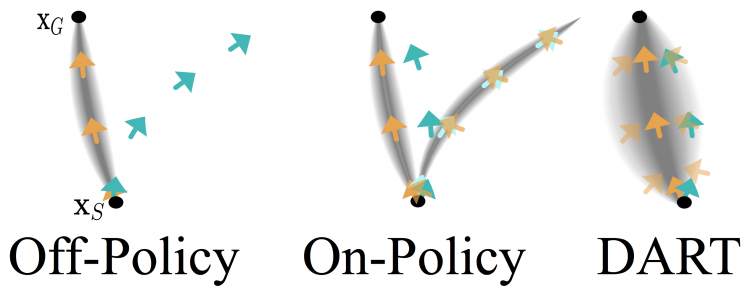
DART: Noise Injection for Robust Imitation Learning
Michael Laskey, Jonathan Lee, Roy Fox, Anca Dragan, and Ken Goldberg
1st Conference on Robot Learning (CoRL), 2017
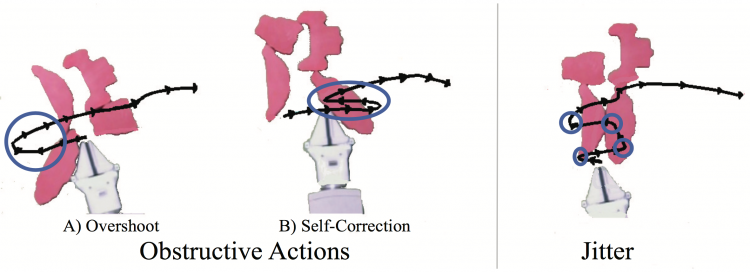
Statistical Data Cleaning for Deep Learning of Automation Tasks from Demonstrations
Caleb Chuck, Michael Laskey, Sanjay Krishnan, Ruta Joshi, Roy Fox, and Ken Goldberg
13th IEEE Conference on Automation Science and Engineering (CASE), 2017
Workshops
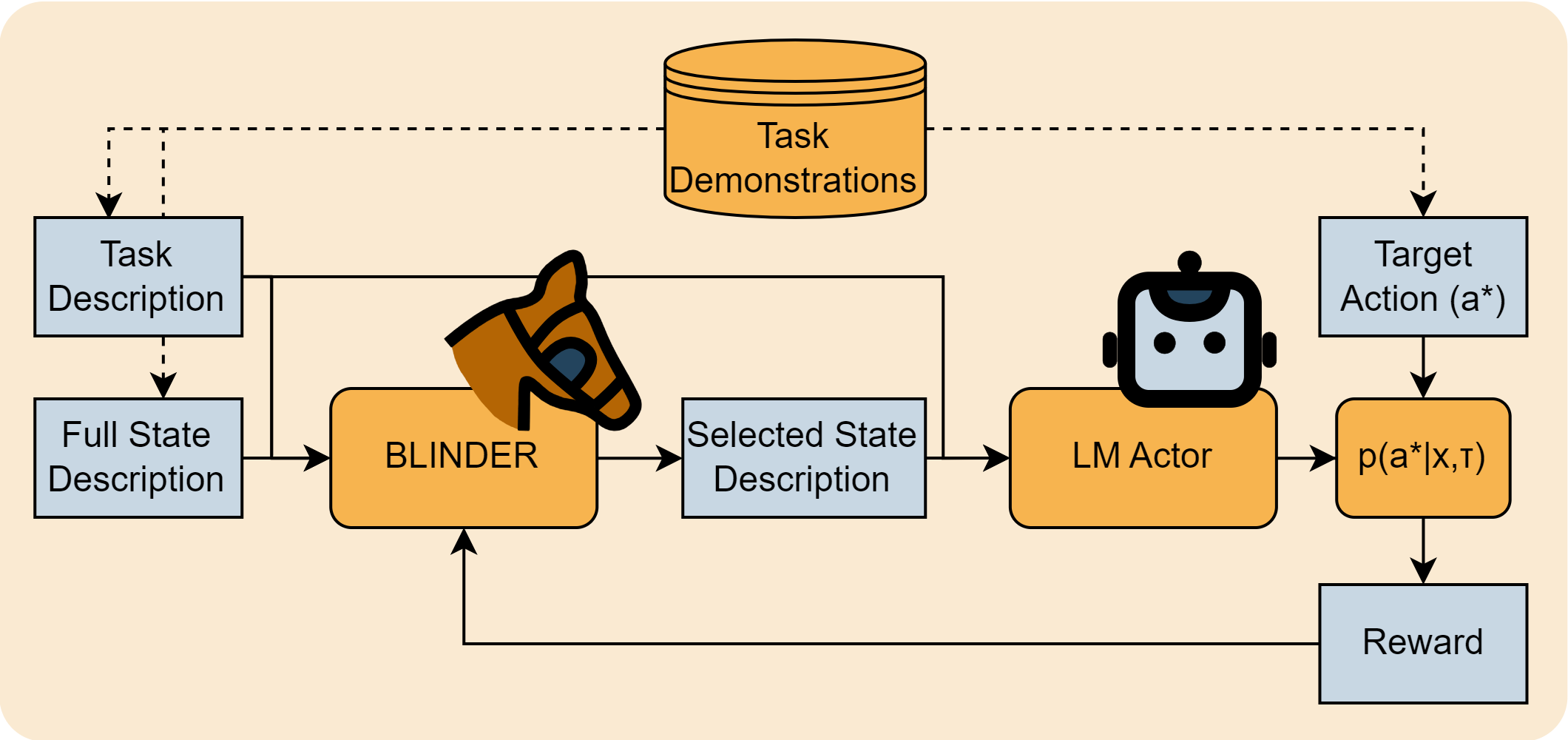
Selective Perception: Learning Concise State Descriptions for Language Model Actors
Kolby Nottingham, Yasaman Razeghi, Kyungmin Kim, JB Lanier, Pierre Baldi, Roy Fox, and Sameer Singh
Foundation Models for Decision Making workshop (FMDM @ NeurIPS), 2023
Do Embodied Agents Dream of Pixelated Sheep?: Embodied Decision Making using Language Guided World Modelling
Kolby Nottingham, Prithviraj Ammanabrolu, Alane Suhr, Yejin Choi, Hannaneh Hajishirzi, Sameer Singh, and Roy Fox
Reincarnating Reinforcement Learning workshop (RRL @ ICLR), 2023
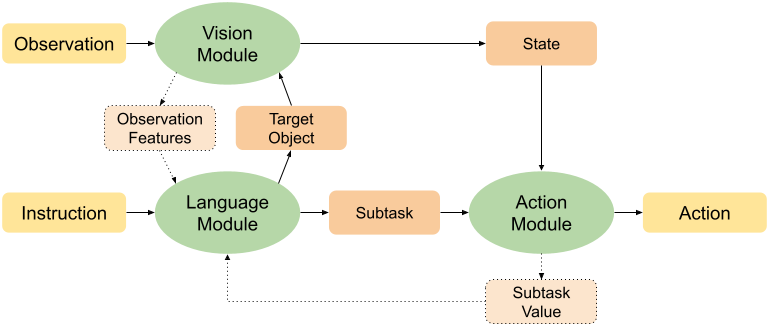
Modular Framework for Visuomotor Language Grounding
Kolby Nottingham, Litian Liang, Daeyun Shin, Charless Fowlkes, Roy Fox, and Sameer Singh
Embodied AI workshop (EmbodiedAI @ CVPR), 2021
Robot Learning with Invariant Hidden Semi-Markov Models
Ajay Kumar Tanwani, Jonathon Lee, Michael Laskey, Sanjay Krishnan, Roy Fox, and Ken Goldberg
Perspectives on Robot Learning: Imitation and Causality workshop (Causal Imit. @ RSS), 2018