Publications tagged "Systems"
Conferences
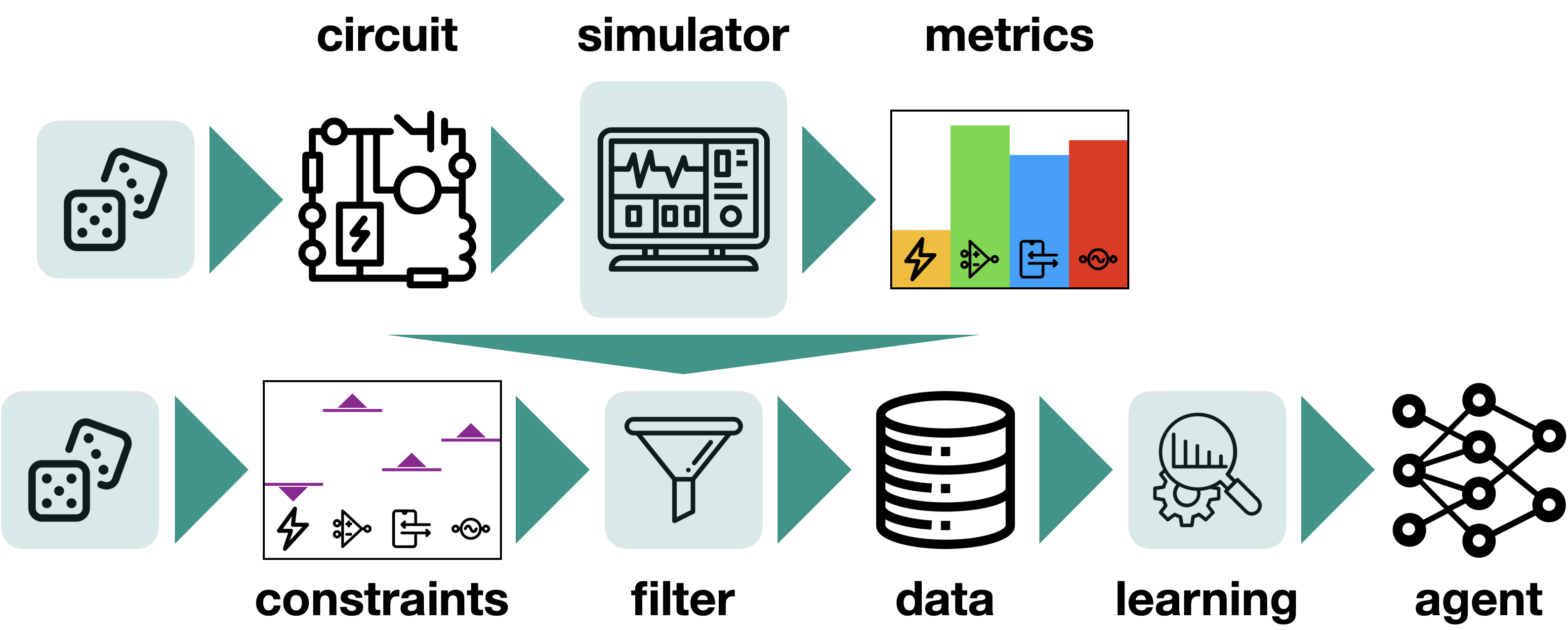
Learning to Design Analog Circuits to Meet Threshold Specifications
Dmitrii Krylov, Pooya Khajeh, Junhan Ouyang, Thomas Reeves, Tongkai Liu, Hiba Ajmal, Hamidreza Aghasi, and Roy Fox
40th International Conference on Machine Learning (ICML), 2023
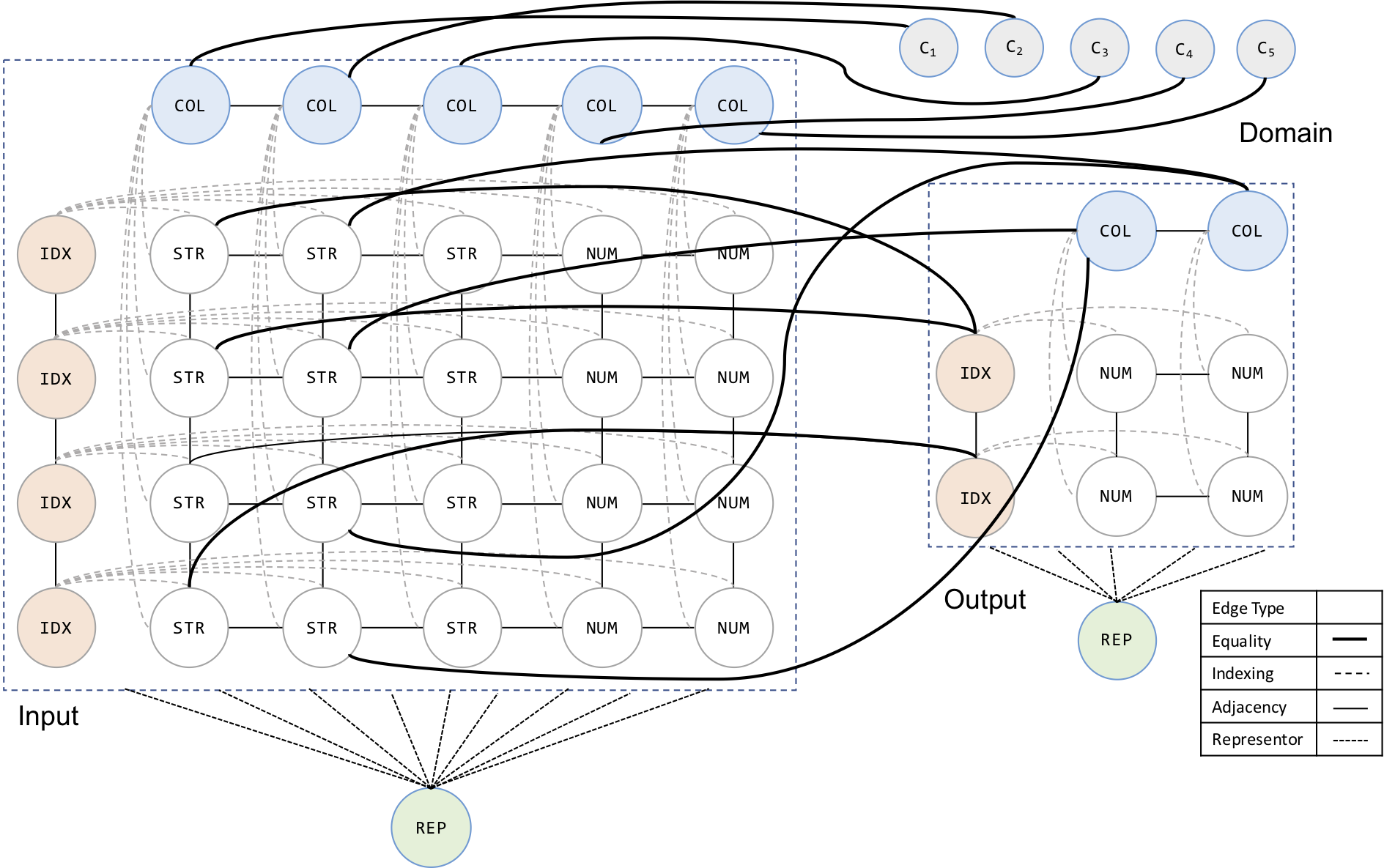
AutoPandas: Neural-Backed Generators for Program Synthesis
Rohan Bavishi, Caroline Lemieux, Roy Fox, Koushik Sen, and Ion Stoica
10th ACM SIGPLAN Conference on Systems, Programming, Languages, and Applications: Software for Humanity (SPLASH OOPSLA), 2019
Multi-Task Hierarchical Imitation Learning for Home Automation
Roy Fox*, Ron Berenstein*, Ion Stoica, and Ken Goldberg
15th IEEE Conference on Automation Science and Engineering (CASE), 2019
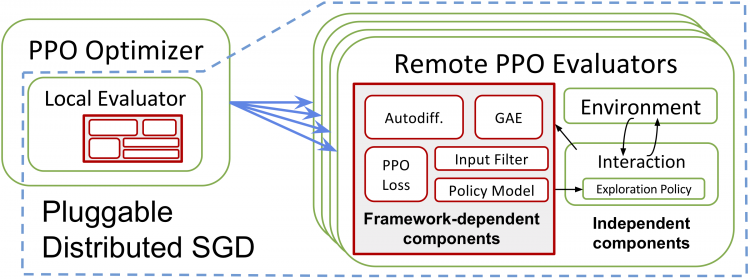
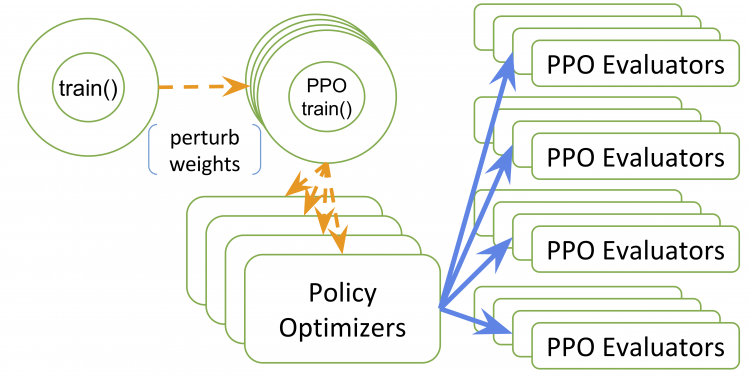
RLlib: Abstractions for Distributed Reinforcement Learning
Eric Liang*, Richard Liaw*, Robert Nishihara, Philipp Moritz, Roy Fox, Ken Goldberg, Joseph Gonzalez, Michael Jordan, and Ion Stoica
35th International Conference on Machine Learning (ICML), 2018
Workshops
Neural Inference of API Functions from Input–Output Examples
Rohan Bavishi, Caroline Lemieux, Neel Kant, Roy Fox, Koushik Sen, and Ion Stoica
Machine Learning for Systems workshop (ML for Sys @ NeurIPS), 2018
Ray RLlib: A Composable and Scalable Reinforcement Learning Library
Eric Liang*, Richard Liaw*, Robert Nishihara, Philipp Moritz, Roy Fox, Joseph Gonzalez, Ken Goldberg, and Ion Stoica
Deep Reinforcement Learning symposium (DeepRL @ NeurIPS), 2017