DART: Noise Injection for Robust Imitation Learning
Michael Laskey, Jonathan Lee, Roy Fox, Anca Dragan, and Ken Goldberg
1st Conference on Robot Learning (CoRL), 2017
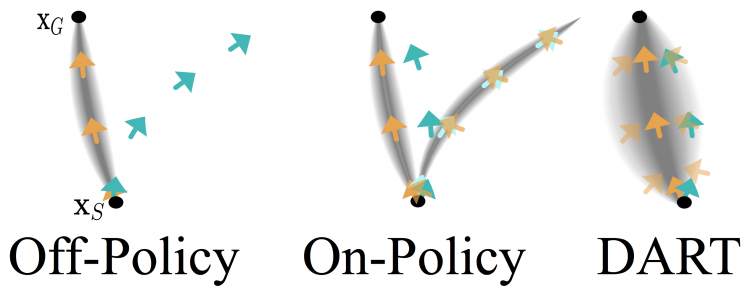
One approach to Imitation Learning is Behavior Cloning, in which a robot observes a supervisor and infers a control policy. A known problem with this “off-policy” approach is that the robot’s errors compound when drifting away from the supervisor’s demonstrations. On-policy, techniques alleviate this by iteratively collecting corrective actions for the current robot policy. However, these techniques can be tedious for human supervisors, add significant computation burden, and may visit dangerous states during training. We propose an off-policy approach that injects noise into the supervisor’s policy while demonstrating. This forces the supervisor to demonstrate how to recover from errors. We propose a new algorithm, DART (Disturbances for Augmenting Robot Trajectories), that collects demonstrations with injected noise, and optimizes the noise level to approximate the error of the robot’s trained policy during data collection. We compare DART with DAgger and Behavior Cloning in two domains: in simulation with an algorithmic supervisor on the MuJoCo tasks (Walker, Humanoid, Hopper, Half-Cheetah) and in physical experiments with human supervisors training a Toyota HSR robot to perform grasping in clutter. For high dimensional tasks like Humanoid, DART can be up to 3x faster in computation time and only decreases the supervisor’s cumulative reward by 5% during training, whereas DAgger executes policies that have 80% less cumulative reward than the supervisor. On the grasping in clutter task, DART obtains on average a 62% performance increase over Behavior Cloning.