Publications tagged "Partial observability"
Conferences
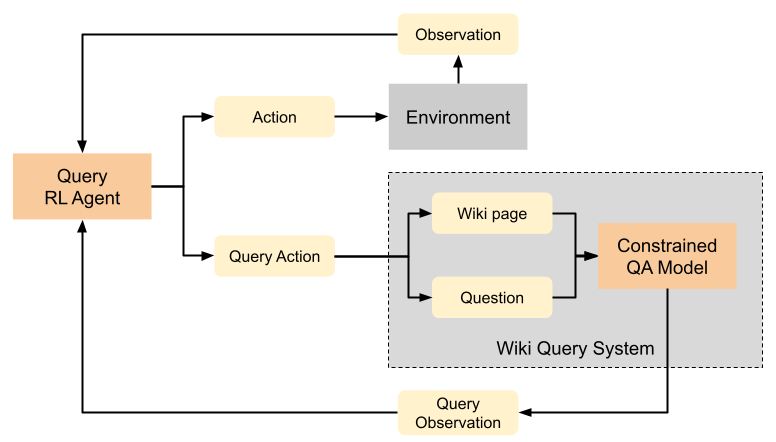
Learning to Query Internet Text for Informing Reinforcement Learning Agents
Kolby Nottingham, Alekhya Pyla, Sameer Singh, and Roy Fox
Reinforcement Learning and Decision Making (RLDM), 2022
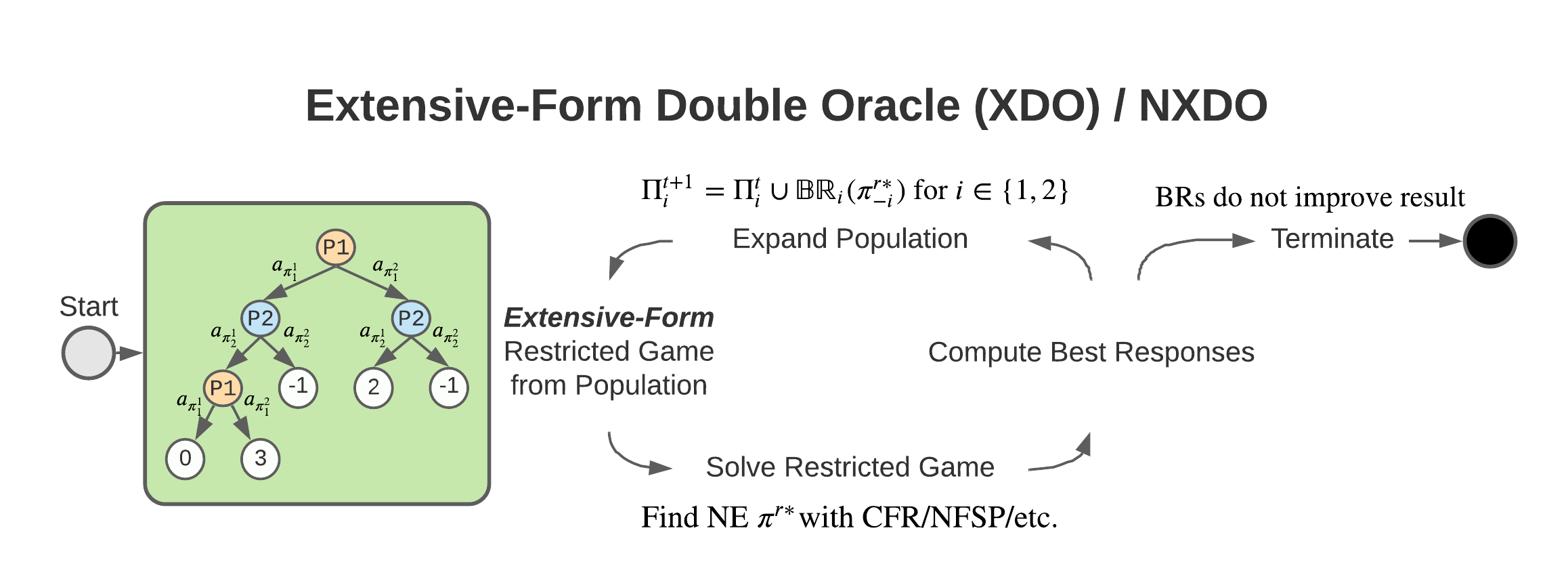
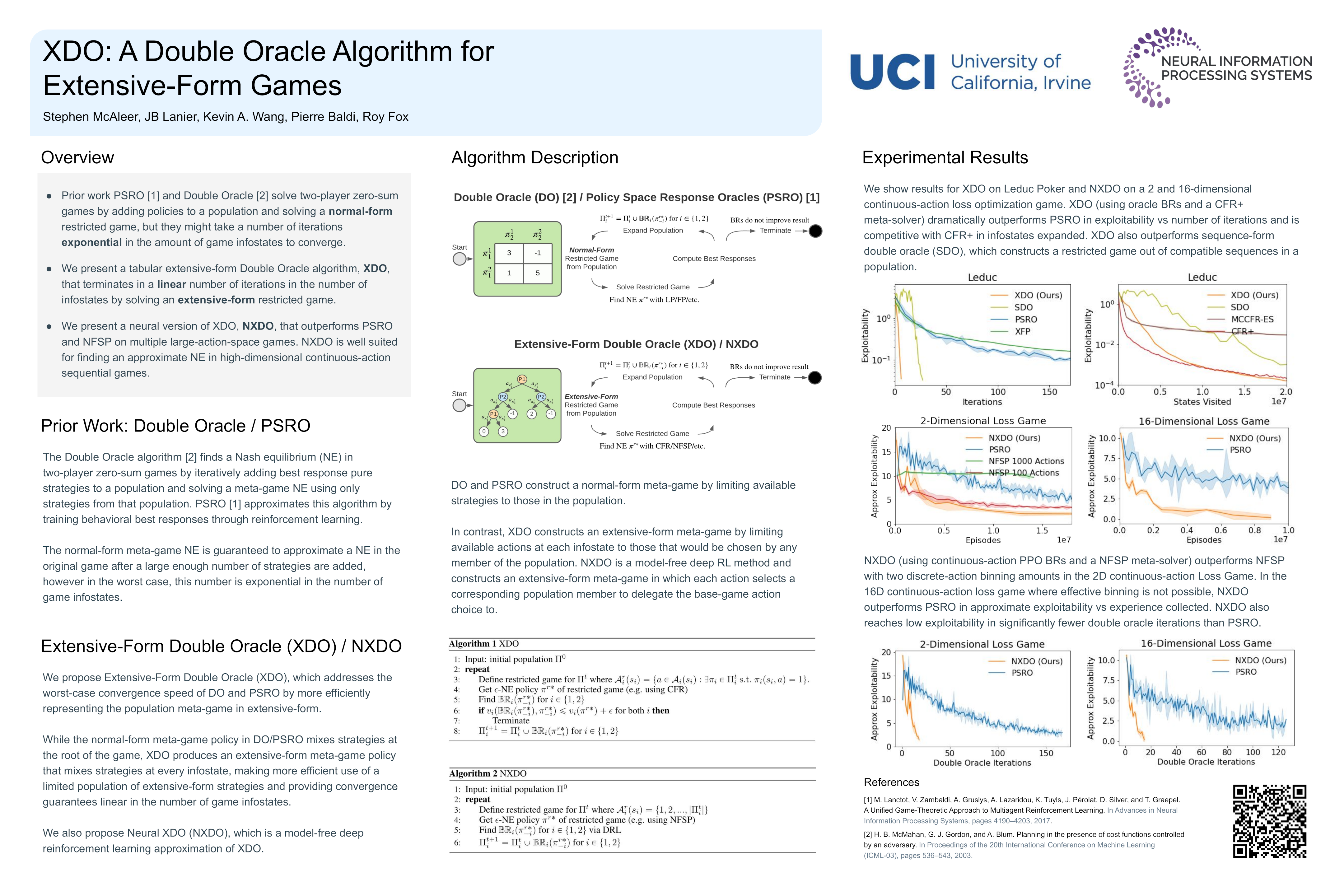
XDO: A Double Oracle Algorithm for Extensive-Form Games
Stephen McAleer, JB Lanier, Kevin Wang, Pierre Baldi, and Roy Fox
35th Conference on Neural Information Processing Systems (NeurIPS), 2021
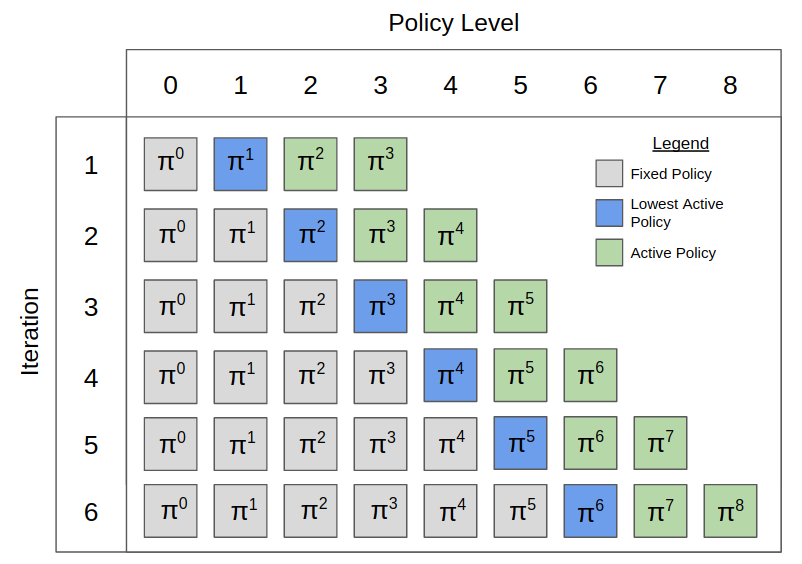
Pipeline PSRO: A Scalable Approach for Finding Approximate Nash Equilibria in Large Games
Stephen McAleer*, JB Lanier*, Roy Fox, and Pierre Baldi
34th Conference on Neural Information Processing Systems (NeurIPS), 2020
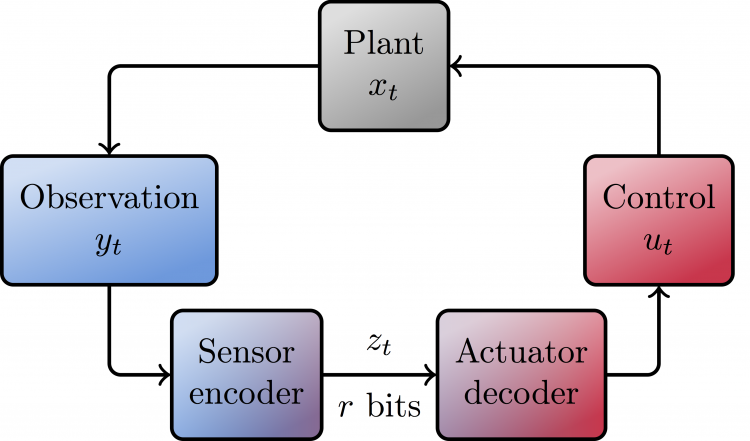
A Multi-Agent Control Framework for Co-Adaptation in Brain-Computer Interfaces
Josh Merel*, Roy Fox*, Tony Jebara, and Liam Paninski
27th Conference on Neural Information Processing Systems (NeurIPS), 2013
Workshops
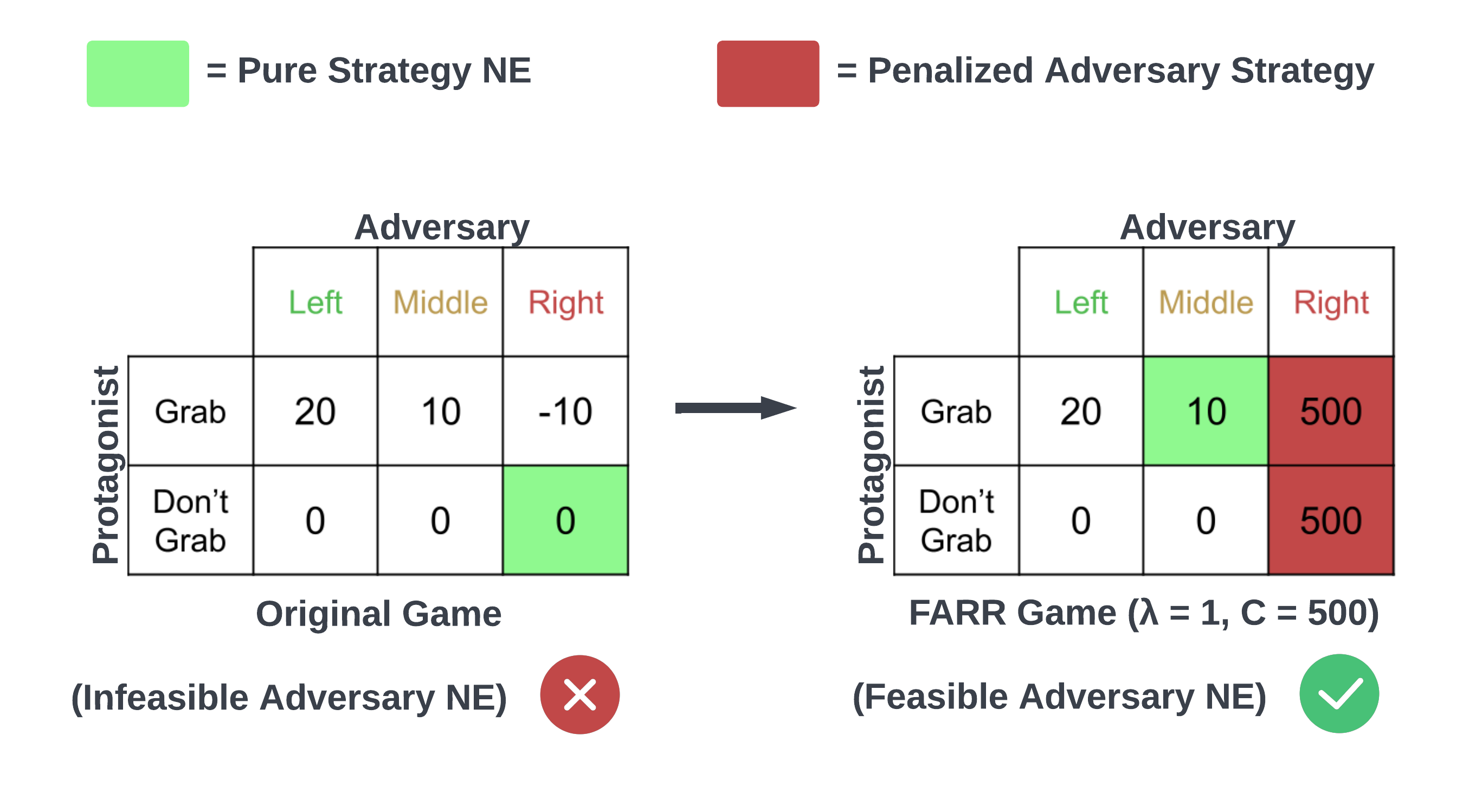
Feasible Adversarial Robust Reinforcement Learning for Underspecified Environments
JB Lanier, Stephen McAleer, Pierre Baldi, and Roy Fox
Deep Reinforcement Learning workshop (DRL @ NeurIPS), 2022
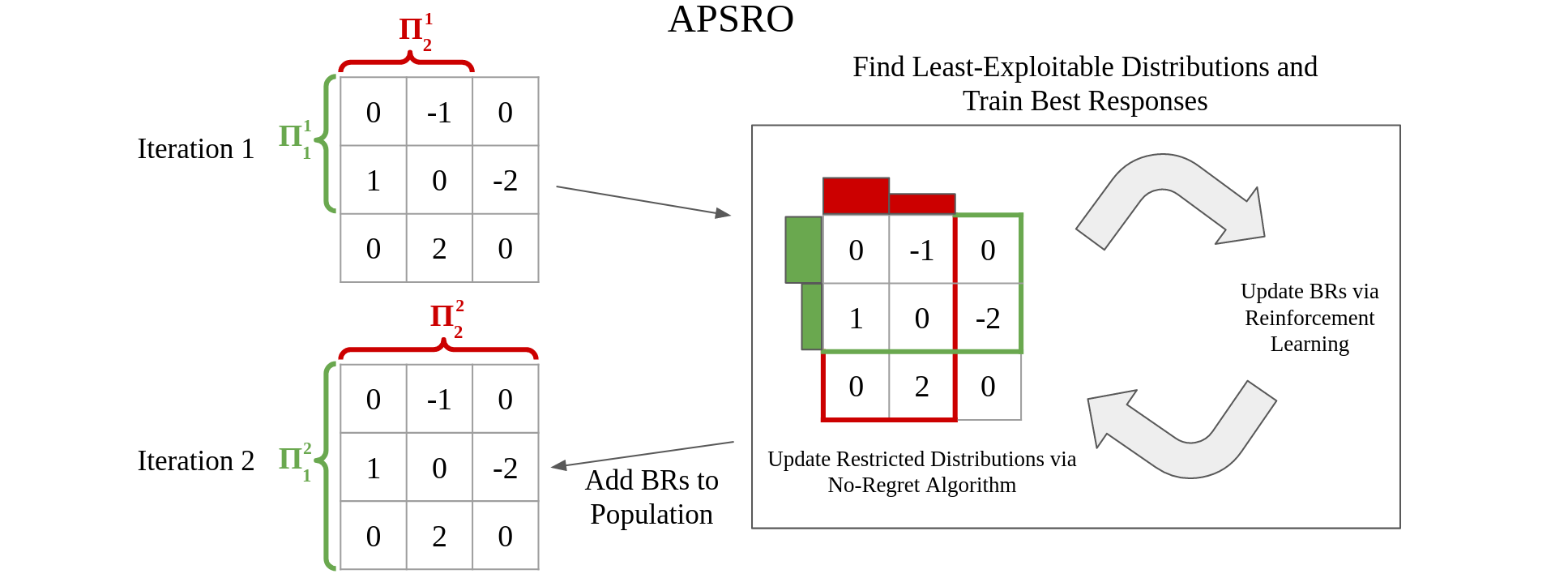
Anytime PSRO for Two-Player Zero-Sum Games
Stephen McAleer, Kevin Wang, JB Lanier, Marc Lanctot, Pierre Baldi, Tuomas Sandholm, and Roy Fox
Reinforcement Learning in Games workshop (RLG @ AAAI), 2022
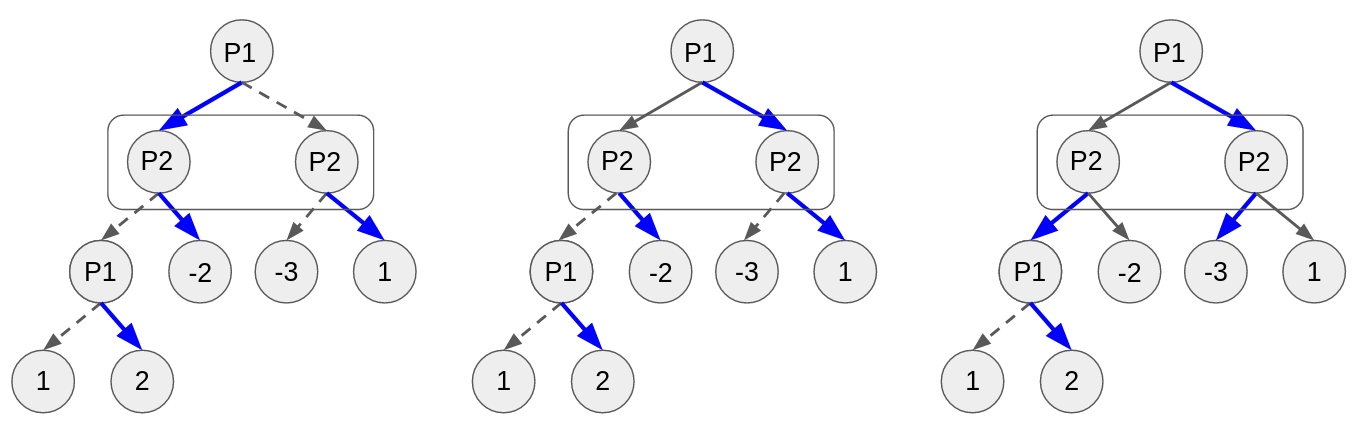
CFR-DO: A Double Oracle Algorithm for Extensive-Form Games
Stephen McAleer, JB Lanier, Pierre Baldi, and Roy Fox
Reinforcement Learning in Games workshop (RLG @ AAAI), 2021
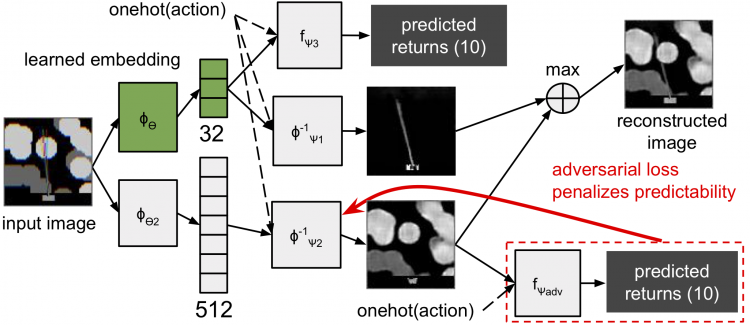
Task-Relevant Embeddings for Robust Perception in Reinforcement Learning
Eric Liang, Roy Fox, Joseph Gonzalez, and Ion Stoica
Prediction and Generative Modeling in Reinforcement Learning workshop (PGMRL @ ICML), 2018
{kind=link}